

In 2016, a thunderstrike from Thor – let alone a “power outage” or a “router failure” should not be enough to bring one of the world’s largest companies to its knees. It has never been easier to seamlessly switch to backup systems. The real problem is that many organizations treat their backup systems like a summer home. Giving it attention for a few months out of the year and the occasionally-long weekend: it may not be ready for a family to move in after a hurricane rolls-in.
The list of incidents that can cause a failure are infinite, but here are two activities IT organizations can undertake to cross many items off of the list:
- Use a self-documenting CMDB: even putting all the processes in place to manually document invites other priorities to distract you from knowing the correct state of your IT estate.
- If you have DR site (if you don’t, stop reading and get one) – test it on a schedule and ensure it mirrors your production environment as closely as possible (and stays up-to-date, courtesy of #1)
As stated above, the list of what can go wrong is lengthy, but if you have good CMDB you can at least solve the technical problem of what needs to be replicated, so we will focus on the importance of a self-documenting CMDB.
Talking with our end users, we get the sense that many sysadmins, data center managers, and IT Operations Executives worry that their organization could be next. Here are the results from a survey we conducted over the last week:
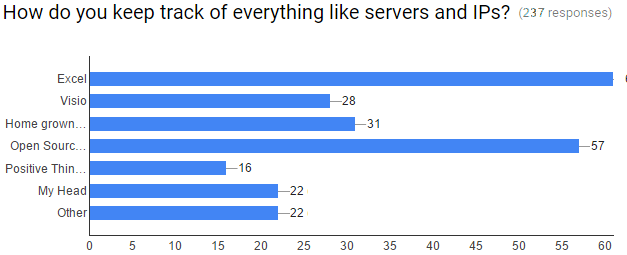
About 60% of the respondents indicated they used Excel/Visio or Open Source software. If you’re using Excel or open source, you are using software that isn’t purpose built for automatically maintaining an accurate picture of your infrastructure and applications.
It introduces human error into the equation because people are required to keep that up to date manually. With IT departments stretched so thin, documentation is often an afterthought, if a thought at all (17% of respondents indicated they document with hopes and memories).
If you don’t have a clear picture of your environment, it’s an unusually difficult task to replicate it to a DR system.
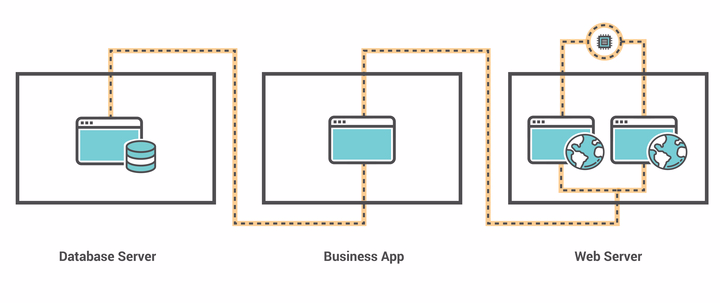
Here is a quick example: Let’s say you have an application. We’ll call it “Flight Reservation App”, and it requires a database. The database is tested on a QA server, and instead of migrating that app to a production server, the QA server becomes the production server because of a time crunch. No one documents that this QA server is now production and it isn’t added to the DR environment. During a failover this converted QA server isn’t there, the database isn’t accessible, the Flight Reservation App which is dependent on it doesn’t work, customers are impacted, your CEO goes to Twitter to apologize, and no one knows why.
A self documenting CMDB leverages multiple discovery protocols (SNMP, SSH, Ping sweeps, WMI, vendor APIs, DNS, mind reading etc.) to automatically discover network devices, IPs, servers, VMs, and application services. And how all of these are connected. When these discoveries are scheduled at regular intervals, IT operations teams can stay focused on the work that needs to be done vs. documenting (accurately, in detail) the work they have done.
When the database for Flight Reservation App QA server becomes production, a self documenting CMDB will capture the change (through dependency mapping) and feed decision support into DR planning.
And if and when disaster strikes, IT operations teams need to figure out what happened, a quick look at a self documenting CMDB helps you cross items off the long list of suspects.