The Top CMDB Discovery Techniques
CMDB discovery is the process that identifies hardware and software IT infrastructure components. These components are also known as configuration items (CIs) and populate the Configuration Management Database (CMDB) with associated attributes such as their name, IP address, and version number.
CMDB discovery uses various automated techniques for collecting the attribute information from remote targets such as servers, storage, databases, cloud resources, applications. The mechanisms for automatic discovery have evolved in recent years to the point that manual information entry is considered a last resort.
This article will review core CMDB discovery concepts and explain why large-scale IT service management requires automated discovery.
A summary of CMDB discovery techniques
A CMDB maps applications and business processes to their underlying hardware and software components to help IT managers gain contextual insights that help make the execution of their daily tasks more efficient.
Enterprise IT infrastructure includes hundreds of thousands of hardware and software components with varying lifecycles and relationships, especially when considering virtual machines, storage volumes, public cloud services, and containers. The sheer volume and complexity of enterprise IT environments have driven continued innovation in CMDB discovery.
The table below describes 12 common CMDB discovery techniques.
12 CMDB Discovery Techniques
| CMDB Discovery Technique | Description |
|---|---|
| Ping sweep | Basic ICMP Ping is used to discover IP endpoints used for further detailed inspection using other techniques presented in this table. |
| Domain Name Service (DNS) | A reverse DNS lookup helps discover the name of an IP endpoint using its IP address. |
| Secure Shell (SSH) | SSH can be used for securely collecting inventory (such as CPU, memory, disk) information from a Linux or Unix OS instance. |
| WMI | When accessed remotely, WMI serves the same purpose as Linux SSH for discovering the systems inventory of a Microsoft Windows OS instance. |
| SNMP | The SNMP protocol collects data from network targets querying different MIB (Management Information Base) nodes implemented on the targets. |
| Netflow | Netflow captures traffic flows between nodes revealing information about the applications behind the traffic generated across the network. |
| NMAP | NMAP is a free tool used for conducting security audits which is helpful for discovering open TCP ports and running services. |
| Packet Capture | Packet capture is a function supported by software or hardware appliances to record and analyze the contents of IP packets transferred across a network. |
| IPMI | The IPMI standard monitors a server’s hardware attributes such as power supply, firmware, and temperature. |
| Configuration automation tools | Tools, such as Chef and Puppet, that automate tasks like installing OS patches on hosts, are a helpful source of inventory and attributes. |
| Application Programming Interfaces (API) | APIs can be used to collect attributes from a variety of platforms such as AWS, VMware hypervisors, Kubernetes clusters, blade servers, or storage arrays (even though some storage vendors rely on SMI-S instead of API). |
| Agents | Agents installed on various OS types can collect inventory information not available remotely. |
In the following sections, we will talk about the core concepts of application discovery and the most current techniques used to maintain the updated CMDB.

Examples of configuration items (CIs)
A configuration item is an entity used to provide an IT service. Each CI has its characteristics, such as classification, type, attributes, and status in its lifecycle. The attributes include the relationships a CI has with other CIs and may include customized attributes only meaningful to a particular company, such as a CI’s association with an accounting cost center.
There are various types of CIs such as hardware, software, buildings, or even documents required to deliver an IT service. The diagram below captures the type of CIs that a comprehensive CMDB discovery tool should support.
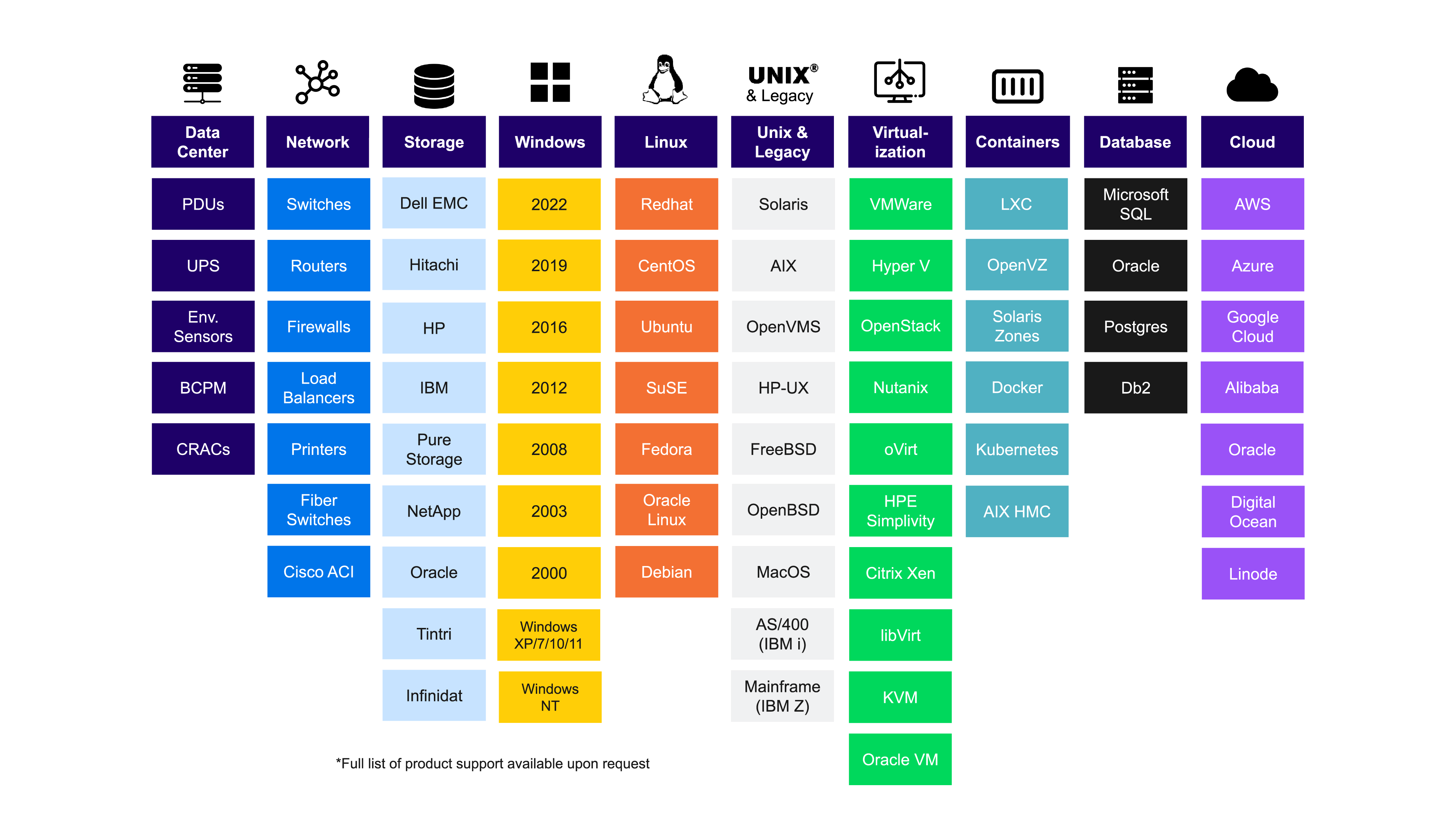
Discovery Chart
A list of typical assets that a CMDB discovery tool must include.
CIs can also be applications, such as instances of SAP, TIBCO, and Microsoft Exchange, which are traditional applications running in a data center. The last few years added new CIs to the list, like web-based applications, microservices, Kubernetes clusters, and PaaS offerings.
The common categories of CIs are:
- Hardware and other compute platforms. Hardware CIs include servers, network devices, computers, laptops, racks, and other hardware components that support an IT service. Virtual machines also fall in this category. Companies have also begun including the computers used by remote workers as records in CMDBs to manage their security and performance more effectively. Peripherals like mobile devices, keyboards, and mouses are sometimes recorded in a CMDB as well.
- Software. These CIs are used to record the company’s software assets. They are artifacts installed on an Operating System and discovered as a process (in the case of Linux) or a registry key (in the case of Windows). Middleware (such as Redis), databases (such as MySQL), web servers (such as NGINX), caches (such as F5), and instances of software platforms used for inter-application messaging (such as Kafka) belong to this category.
- Public Cloud. These types of CIs are any public cloud service used to support IT applications. CIs can contain subscriptions, virtual networks, resource groups, web servers, Kubernetes instances, and microservices. Public cloud providers offer over a hundred services, from storage and database to data analytics. These CIs are tracked by the cloud provider and synchronized with a federated CMDB via the APIs provided by the cloud vendors. A CMDB must integrate with the APIs of many cloud providers such as AWS, Microsoft Azure, Google Cloud, Oracle Cloud, Alibaba, Digital Ocean, and others.
- Applications. Applications may be self-managed (such as an instance of SAP ERP) or be a SaaS offering (such as Salesforce.com). They are typically discovered as an installation folder that contains configuration files or as an open TCP port. Having an application CI helps IT establish its relationships with the infrastructure components required to host and access it, allowing the correlations of incidents and managing the entire application stack through its lifecycle for security and a range of other purposes.
What about containers in a CMDB?
Virtual machines that run on hardware platforms are often recorded as a CI, but containers are too ephemeral to be registered in a CMDB. However, container orchestration platforms — like Kubernetes — often offer an API to discover non-ephemeral components that are better suited for a CMDB like pods (a group of containers) or namespaces (a virtual Kubernetes cluster).
The pros and cons of different CMDB discovery techniques
There are many ways to discover configuration items and their associated attributes to populate a CMDB. The table below dives deeper into the common CMDB discovery techniques by explaining their respective advantages and disadvantages.
CMDB Discovery Techniques Pros and Cons
| CMDB Discovery Technique | Description | Pros | Cons |
|---|---|---|---|
| Ping sweep | This approach consists of pinging all IP addresses on known network segments from a central device. | It is the cheapest and fastest way to discover CIs deployed on a network from any OS with no specialized software and with no credentials needed. | Some devices might not support ping responses or have ping responses disabled.
Some network segments may not be reachable from a central device. Correlating device with IP depends on reverse DNS lookup, and is directly tied to DNS accuracy. |
| Domain Name Service (DNS) | DNS resolves an IP address for a provided hostname or domain name.
The CMDB discovery uses the DNS in reserve. It looks up the registry to find the name of a host by providing its IP address, often identified using a ping sweep. |
DNS is a reliable approach for discovering device names in a network.
DNS reverse lookup avoids having to memorize IP addresses and allows CMDB users to refer to servers by their names based on an intuitive naming convention established by the company. |
DNS accuracy becomes critical |
| Secure Shell (SSH) | It allows establishing a session with a Linux or UNIX system and capturing OS data from the device using remote shell commands. This access method is secure since SSH encrypts the communication. | SSH is enabled on most distributions of Linux devices, so as long as you have credentials to connect to the systems, it is easy to use for gathering data.
It scales well as it does not require much network bandwidth. |
SSH is only available on Linux and Unix hosts and requires credentials for obtaining access.
Some companies may have concerns about allowing remote access to critical servers. |
| WMI | This technique remotely accesses the Windows Management Instrumentation (WMI) service on a Microsoft Windows OS host to gather system information. | Windows OS includes WMI, which is the source of truth for systems configuration information. | You must configure the Windows Firewall and User Account Control (UAC) settings to allow remote WMI access.
WMI queries require credentials for access. |
| SNMP | The common SNMP protocol stores network information in the form of a Management Information Base (MIB), which is ideal for collecting attributes from network CIs. | The implementation of the SNMP standard is consistent across different vendors and operating systems making it a reliable and rapid method for data collection. | As a common and open protocol, SNMP can be vulnerable to attacks.
Only the third version of the SNMP (v3) standard provides encryption. |
| Netflow | Netflow captures packets entering and exiting network interfaces and organizes them into flow records.
The records contain information about the TCP ports (among other data) that can reveal the names of the applications generating the network traffic. |
The Netflow standard and its successor, IP Flow Information Export (IPFIX), provide insights about the application packets traveling over the network, which are valuable attributes for populating a CMDB. | Netflow is compute-intensive and bandwidth-intensive, so it’s often disabled or used at low sampling rates. |
| NMAP | NMAP is a free tool used for network discovery and security audits, but it can also be used for discovering which services run on which ports. | NMAP works best when used in combination with other techniques such as NetFlow for triangulating service to port mapping information. | Restrictive firewall rules hamper NMAP’s ability to discover port and service information.
NMAP’s discoveries are considered best guesses in many cases, so their accuracy must be further verified using other techniques such as scanning host configuration logs. |
| Packet Capture | Packet capture goes beyond the packet headers (containing the TCP and IP address information) analyzed by NetFlow and captures the payloads (or content) of the packets being transferred over a network. | The packet payloads can be analyzed to precisely identify which applications are communicating and map them to ports and IP addresses. | Packet capture is resource-intensive and cannot be enabled all the time on all network devices. |
| IPMI | IPMI leverages a computer’s standard baseboard management controller (BMC) to collect information about its hardware, firmware, and operating system. | IPMI provides helpful attributes to populate a CMDB, such as a host’s BIOS version and hardware configuration. | Configuring IPMI can be challenging for IT administrators with less experience.
IPMI could introduce security vulnerabilities if not configured correctly. |
| API | Almost all software platforms have an Application Programming Interface (API).
Examples are Computer platforms such as hypervisors, container orchestrators, or public cloud services, Middleware platforms such as message buses or databases, and Packaged applications such as Oracle ERP or SAP. |
APIs are a rich source of software asset inventories and configuration attributes and should not be overlooked for populating a CMDB.
RESTful APIs are common in modern software products and standardize the data retrieval formatting, but not the query language or the schema. |
Each API has a different schema that integration engineers must learn before querying data.
Mastering a multitude of schemas can be overwhelming. CMDB project planners should select CMDB platforms that have pre-built integrations with many third-party APIs. |
| Configuration Automation Tools | System configuration automation tools like Chef and Puppet install agents on hosts and use them to execute commands required to maintain a declared configuration state.
They represent a rich source of host inventory and associated attributes. |
Configuration automation tools include detailed system configuration information such as the OS patch version.
The information stored in their repositories is reliable since it is actively used for system configuration. |
System admins don’t install configuration automation agents on all of the hosts in their environment, so they are best used to augment other discovery techniques.
Modern containerized applications designed based on immutable infrastructure principles don’t use configuration automation agents. |
| Agents | Agents are scripts or lightweight programs that run on nodes or hosts to collect information not accessible using remote access protocols such as SSH and remotely-accessed WMI. | Agents can collect detailed system information such as OS patches, disk size, names of the processes running on a CPU, and the list of nodes with an active connection to a database.
Agents can usually be customized to collect just about any data specific to a bespoke application environment. |
Agent deployment can be expensive and time-consuming, especially for large enterprise environments, adding months to the timeline of a CMDB implementation project.
It’s important to choose a CMDB vendor that supports agents for various operating systems (such as AS 400 and Solaris) to cover legacy application environments. |
CMDB Use Cases
A CMDB supports the practices defined by the ITIL framework that represent an enterprise IT department’s daily activities. A CMDB makes those practices more efficient to execute. Below are examples of such practices and examples of the efficiency gains delivered by a CMDB populated with effective discovery methods.
CMDB Use Cases
| ITIL Practice | Examples of the efficiency gains provided by a CMDB |
|---|---|
| Incident management | The relationship information stored in a CMDB helps determine the impact on applications when a component fails. |
| Problem management | The attributes and relationships stored in a CMDB help the root cause analysis of recurring problems. |
| Change management | The information about the relationship between CIs helps plan changes with minimal impact on applications. |
| Release management | The stored version numbers of supporting components help determine compatibility when releasing new software. |
| Availability Management | A CMDB helps shorten the mean time to repair by identifying application dependencies during troubleshooting. |
CMDB Discovery Recommendations
Avoiding mistakes while discovering assets for a new CMDB implementation can save weeks and months. The recommendations below represent best practices designed to avoid common mistakes.
Use agentless-based discovery to discover most CIs.
There’s no one-size-fits-all answer to the agentless vs. agent-based debate. However, agentless techniques have a much lower administrative overhead and allow reaching almost any type of device visible in the network. An agentless approach helps gather most required information without dedicating a project phase to deploying agents on hundreds of hosts.
Use agent-based discovery when agentless isn’t sufficient.
While agentless discovery has its advantages, there are cases where it isn’t enough to meet requirements. In those cases, agent-based discovery is preferable. The three most common examples where agent-based discovery is advantageous are:
- When network connectivity with the CMDB is unavailable or unreliable.
- When an application requires in-depth information because of its criticality.
- When enterprises need to collect information from legacy platforms or laptops and desktops used by remote workers. These devices are not always online, which makes them difficult to discover without an agent.
However, make the decision to use agent-based discovery on a case-by-case basis and ensure the reliability and visibility benefits outweigh the additional operational overhead.
Select a vendor that supports legacy platforms.
Most large enterprises have legacy applications that run on less popular platforms. Examples include applications running on mainframes, supercomputers, or customized applications that run on OS flavors such as Sun Solaris, HP UX, AS 400, or FreeBSD. Legacy applications are often in most need of being captured in an inventory. Make sure to select a CMDB tool or discovery technique that supports the right mix of vendors.
Consider all public cloud providers.
Choosing a discovery technology that supports multiple public cloud providers allows adding new cloud providers over time without the need to change your CMDB technology. Most vendors focus on Amazon Web Services (AWS), but not all vendors fully support Microsoft Azure, Google Cloud, Alibaba, Oracle Cloud, and Digital Ocean.
Discover CIs with fingerprinting technology and preset rules.
CMDB discovery can detect software running on an OS instance based on the processes (or services) that run on the OS and the system’s configuration. For example, advanced CMDB solutions would detect an instance of MySQL running on Linux via remote SSH by using preset rules that recognize the names of the services running on the OS instance. This technique, known as fingerprinting, can save countless hours and greatly reduce the operational costs of a CMDB project.
Choose a CMDB with an open architecture.
Once the CIs are discovered and stored in a CMDB, other applications should use the CMDB as the source of truth. Configuration management tools such as Ansible and Terraform can use the application groupings stored in a CMDB to discover all the assets that support an application. Advanced CMDB solutions support many integrations, an open API, and a well-defined query language to synchronize the information stored in the CMDB with other tools.
Choose a CMDB that can use multiple discovery methods and correlate data
A CMDB’s key value is the variety of attributes supported for its configuration items. The attributes must be collected from different data sources. For example, a CMDB platform must query the vSphere REST API on a VMware platform to discover the relationships between virtual machines (VM) and the VMware hosts. However, the information about the software installed on each VM comes from SSH or WMI. Therefore, a CMDB platform must be able to uniquely identify each CI and correlate all available information about that CI across multiple integrations (such as vSphere, SSH, WMI) and present a complete set of attributes for each configuration item.


Fastest time to value with easy implementation and agentless asset discovery

Comprehensive hardware and software inventory management

Broadest discovery from legacy technology to the latest cloud and containers
Conclusion
ITIL defines best practices for delivering services through various processes such as incident management, problem management, request management, and knowledge management. CMDB sits at the core of these processes as the common data layer sharing information about configurable infrastructure items that support business application services. CMDB’s effectiveness and accuracy depends on the methods and strategy of collecting the infrastructure configuration – a process referred to as CMDB Discovery.
A successful CMDB discovery initiative requires support for a dozen techniques (such as Ping, SSH, SNMP, and agents), legacy platforms (such as HP UX, and mainframes), and public cloud platforms (such as Google Cloud, Alibaba, and Oracle Cloud). Once the CIs are discovered and mapped to applications, a CMDB must allow integration with third-party tools via an API and a query language.