
Monitoring System Initiated Automatic Failover – Including a Nagios Example
When running Device42 in a Warm HA (High Availability) configuration, in the event the primary instance fails, the secondary must be ‘promoted’ from the warm-standby state [job processing, scheduler, & backups disabled] to the primary [fully active] state. This can be accomplished with a simple API call, and therefore can easily be configured to trigger automatically using just about any monitoring solution that can detect a state change.
To toggle between warm standby and production states, POST the ‘appliance_mode’ parameter to: /api/1.0/appliancemode/
e.g. sending:
“appliance_mode=production” toggles a warm standby appliance to production mode
…or…
“appliance_mode=standby” toggles a production appliance to warm standby mode
This API POST will toggle the target Device42 instance from standby to production:curl -X POST -d “appliance_mode=production” -u ‘d42admin:default’ https://Device42Instance:4343/api/1.0/appliancemode/ –insecure
By embedding the above call into a script that is called by your monitoring system in response to a failure event, the failover process can be fully automated. The following example uses Nagios along with the above example API call to automate a Device42 warm standby to production in a failover scenario.
Nagios Automated Failover Example:
1. First, add the following configuration github link to your Nagios host file:
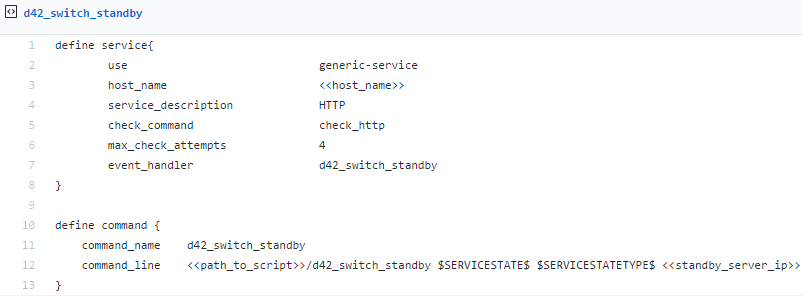
- Second create a script file similar to this example github link:
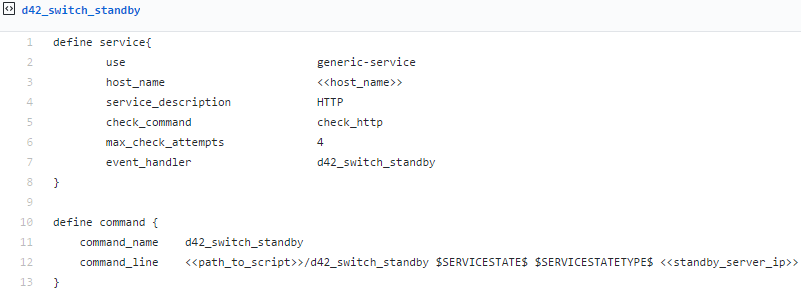
The above example (if utilized exactly as written) only has automated failover to the secondary instance enabled [no failback]. The provisions to failback are present in the example script [see the commented lines following OK), lines #11+12], but are not currently enabled. Though it may be unnecessary depending on the failure mode of the primary instance, it’s not a bad idea as a precaution to have your production script attempt to send an API call to the primary instance, placing it into standby and thus preventing it from running jobs should it recover until a failback is intentionally initiated.
- Please ensure the script runs as the proper Nagios user, and is also allowed execution permissions:
( $ chown nagios:nagios «file_path» && chmod 755 «file_path» ) - The current example works by using “check_http” to detect failure, but it’s entirely possible to change it to utilize other commands
- The production DNS entry must be edited to point at the IP of the new primary Device42 instance to allow reachability via the same URL. For Windows DNS environments, this can be accomplished with the following powershell script example – see usage examples detailed by the author in this blog post. For other platforms, a custom script will have to be written and used.
-
How it works:
If the main Device42 server instance goes down and this is detected by monitoring, the above script switches the appliance mode of the secondary server to production with a POST call to the RESTful API endpoint /api/1.0/appliancemode/ with payload “appliance_mode=production”.
If main server comes back up again, the script can switch the secondary appliance’s mode to back to standby, allowing the first server to once again become authoritative. Uncomment lines #11 & 12 to allow this to happen automatically. Ensure provisions have been made to switch the DNS entry back to the primary instance’s IP address, as well.
If you aren’t a Device42 user yet, today is a great day to start! Device42 is completely FREE for 30 days, no strings attached.
Grab your Device42 trial today!