Vulnerability Management Best Practices
Vulnerabilities are prevalent in all application infrastructure environments, regardless of business or industry, and represent one of the most persistent and dangerous threats to organizational security. Vulnerabilities come in all shapes and sizes, and many lead to breaches; organizations are largely exposed to them due to slow remediation times and a lack of visibility into critical assets.
Vulnerability management is more than simply knowing what vulnerabilities impact your organization and the security of your bottom line. It’s the ability to take a holistic approach to reducing the risks posed by vulnerabilities by addressing the full lifecycle of vulnerability management, which includes identifying vulnerabilities, prioritizing them based on impact on critical applications, and tracking them through remediation.
Many organizations take a reactive approach to vulnerability management that often leads to patching the wrong vulnerabilities. They chase the Common Vulnerabilities and Exposures (CVEs) that are rated “critical” even when they are less relevant to their production application environments. Meanwhile, they allow riskier exposures to persist simply because they are a lower severity score. The result is wasted resources and persistent risk.
With an effective vulnerability management lifecycle, organizations can identify the most relevant vulnerabilities and ensure that their patching strategy reduces their risk exposure. This article outlines the best practices for creating and maintaining a strong vulnerability management program.
Summary of key vulnerability management best practices concepts
| Best practice | Description |
|---|---|
| Ensure proper asset discovery and inventorying | Organizations can only protect what they know about, which means asset visibility is needed across a system with diverse deployments. This should extend beyond just basic inventory and include continuous monitoring and classification. |
| Integrate up-to-date CMDB information | An up-to-date CMDB ensures that organizations have an accurate picture of their environment. This enables vulnerability management efforts to target the assets and data flows in their environment. |
| Include dependency mapping | Understanding interconnected system dependencies helps uncover hidden risk paths. In turn, this helps vulnerability remediation be more targeted and effective. |
| Optimize the vulnerability lifecycle | Organizations should reduce manual overhead by automating wherever possible while ensuring that their testing and production environments are identical. This minimizes human errors and improves the efficacy of remediation deployments. |
| Choose an effective set of measures | Choosing effective measurements helps organizations reduce their risk posture over time. This goes beyond metrics like mean time to remediation and includes things like scan coverage, rate of recurrence, and more. |

Discover assets automatically including hardware, software, and cloud infrastructure
Match the assets against your software and hardware license agreements

Comply with your service license needs comprehensively and confidently
Ensure proper asset discovery and inventorying
Any organization looking to reduce its overall risk through patching must first know where its assets are and what their impact is on its bottom line. Given the nature of vulnerabilities and their impact on multiple components, asset identification goes beyond simple listing and involves understanding the relationships among components, services, and applications and their relative impact on the overall risk.
For the rest of this section, consider the EternalBlue vulnerability. This vulnerability targeted a zero-day vulnerability within Microsoft’s Server Message Block (SMB) protocol and was assigned a critical rating by Microsoft when it was publicly revealed. It was highly effective, and when exploited correctly, it enabled an adversary to compromise a computer network almost effortlessly.
However, some nuances to this vulnerability could directly impact how an organization would remediate it. For starters, it only applied to SMB v1. It was also only effective against Windows operating systems (a full list of the impacted OSes can be found here).
Asset discovery and metadata
Most IT environments today span varied technology stacks where traditional discovery tools struggle at identifying assets. Without a clear picture of assets and their dependencies, organizations see increased incident response times as teams are required to manually trace the relationships among affected systems.
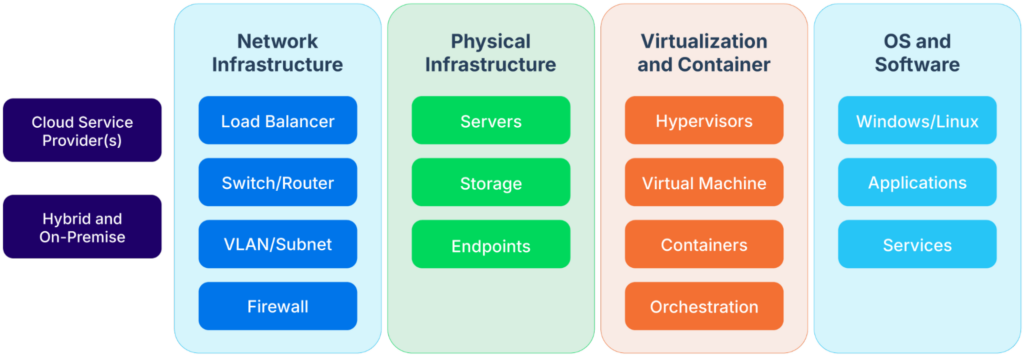
Where assets reside (source)
While knowing where your assets are is imperative, additional information is required for discovery and inventorying to be effective. This includes information such as OS version, installed software data, service configurations, business application mapping, and more.
The depth of this metadata has a direct connection to how vulnerabilities are managed. For example, consider the vulnerability introduced earlier. Imagine that you are in the team responsible for urgently patching all impacted assets. You would need to know:
- Which assets are running Windows (ideally only the impacted ones, but given the scope of the vulnerability, it would most likely start with all Windows assets)
- Of these, which assets have SMBv1 enabled
Getting answers to even these two seemingly simple queries would strain any organization without an effective asset discovery program. You would be forced to do all sorts of crazy, ad hoc queries in a situation that is already time sensitive and high pressure.
However, with an effective asset discovery program, finding this information would be significantly faster. Depending on the platform being used, it could be the work of a few minutes. This significantly increases the speed and accuracy of your response, resulting in a shorter vulnerability period, and decreased risk to the organization.
To get started with your asset discovery program, use the quick reference guide below for the types of metadata you need, grouped by asset type. While you can find a more comprehensive list here, it is more than sufficient to get started and will definitely improve your vulnerability management program.
| Asset Type | Metadata Requirements |
|---|---|
| Network Device |
|
| Cloud Based |
|
| Operating System |
|
| Virtual Machines |
|
| Databases |
|
| Load Balancers |
|

Integrate contextual asset risk information
Asset risk must be integrated with asset discovery and metadata to allow you to prioritize vulnerability remediation based on the context within which an asset runs, rather than just the relative danger of a vulnerability.
For instance, consider the EternalBlue exploit introduced earlier. In the previous subsection, you generated a list of assets both running the Windows OS and using SMB v1. Now you need to start figuring out how to patch the vulnerability.
For most organizations, this would involve a staged patch rollout process. Ideally, you would test the emergency patch on a low-risk asset that will have a negligible impact on the business if something about the patch causes the OS to crash. Then, once the patch has been deployed and confirmed to be working, you’d target progressively higher-impact assets.
During this time, the business may want to put in place emergency monitoring for high-risk assets. For instance, imagine that a Windows Server OS asset running an SQL server with all your customer information was somehow internet-connected and using SMB v1. Disregarding the fact that you should never connect a production server directly to the internet, it is likely that the organization would want to either disconnect the server from the internet (and deal with the disruption) or put in place extremely granular monitoring while the remediation process was being completed.
In both instances, contextual information about the asset would radically change the remediation process. The organization could use this contextual information to create and implement more effective remediation plans.
Continuous discovery
Both of the above sub-sections rely on up-to-date asset inventory. This means you need to go beyond a one-time, static assessment and instead rely on continuous discovery. Modern networks are constantly changing and evolving as new technologies are integrated, devices are updated, and cloud services become more ephemeral.
To support this discovery, tools need to be integrated with IT and security operations. This should include the ability to initiate scans when new network segments or cloud resources go live. Cloud and container assets may require near-real-time updates, while traditional servers, network devices, and OT systems may only require daily, weekly, or monthly scans that balance accuracy with performance impact.
Platforms like Device42 provide this visibility by monitoring everything from rack-level hardware to virtualized systems and hybrid cloud resources. Even more importantly, these platforms give critical context, such as interconnected services and systems and which parts of the business depend on them. This is a critical input when determining what vulnerabilities impact the organization the most.
The diagram below illustrates how this works:
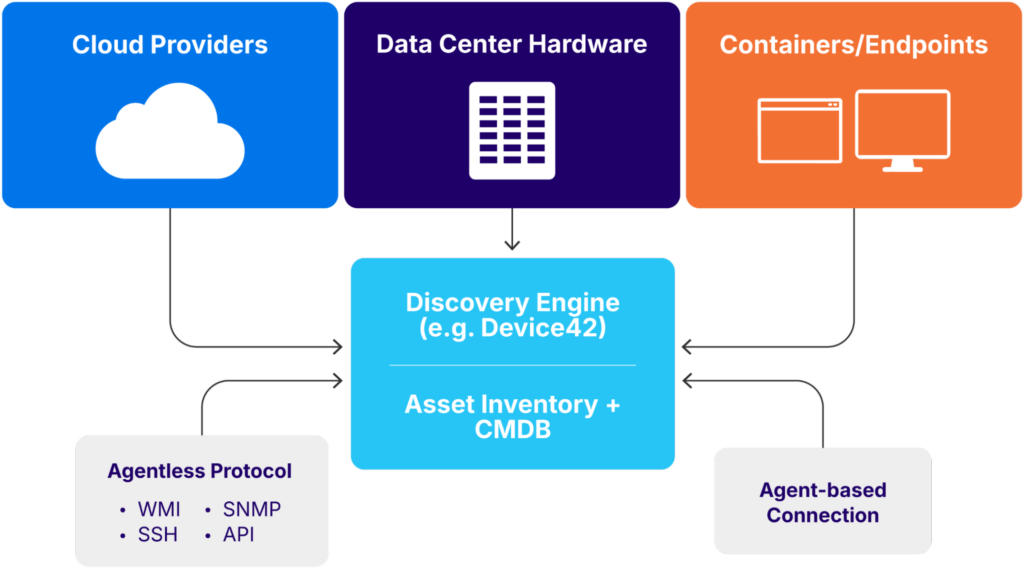
A discovery engine connected to a CMDB (source)
Integrate up-to-date CMDB information
A configuration management database (CMDB) with up-to-date information enables an organization to focus its vulnerability management efforts on its actual operational environment. When done effectively, your CMDB integration provides:
- Asset context through real-time discovery as assets change over time
- Vulnerability prioritization based on actual asset criticality to the organization
- Automated ownership assignment that allows vulnerability remediation tasks to be assigned to the right owner
- Compliance mapping that integrates regulatory and audit data into the vulnerability workflow
Consider the scenario introduced in the previous section. Any organization responding to this vulnerability needs to know which assets are running Windows operating systems (and SMBv1) right now, not one month ago. Only with this information can they make effective, real-time decisions and be confident they are reducing the risk being posed to their systems.
To do this, make sure your discovery tools automatically feed into your CMDB. This ensures that your CMDB has an up-to-date picture of your network, as observed by agent-based and agentless discovery tools. Also, check that any infrastructure changes automatically feed into your CMDB, including any downstream asset and dependency relationship mapping.
Include dependency mapping
Traditional vulnerability management prioritizes based on scoring systems that lack context for the environment in which the vulnerabilities apply. This lack of visibility shows the limitations of severity-only scoring systems. For instance, technical standards such as the Common Vulnerability Scoring System (CVSS) reflect generalized exploitability, providing no consideration of business impact. They treat isolated and interconnected systems equally while failing to identify vulnerability cascade effects in complex environments (e.g., kill chains).
For instance, consider CVE-2025-5279, a vulnerability that involves improper certificate validation in the Amazon Redshift Python Connector for an OAuth plugin. The severity rating is a CVSS score of 7.0, which is considered high. While this is important, exploitation of this vulnerability depends on several factors, including having an insecure connection that allows communication interception in the first place.
Now, imagine an organization receiving a notification for this vulnerability. The organization would need to establish:
- Whether it is using the vulnerable connector.
- If so, whether there are other mitigating factors they already have in place that may mitigate the impact of the CVE.
- If the answer to one is “yes” and two is “no,” then where the vulnerable connector is being used in the code base.
Without in-depth dependency mapping, each of these questions would take significant time to answer. All engineering teams across the organization would need to audit their code, along with any third-party libraries, to see if the connector was used. This step alone would likely take the majority of a two-week sprint cycle. Then, if any instances of the connector are found, a secondary audit would need to be conducted to establish if any mitigating measures are in place. Once again, this would likely take several days. Only then could the organization work toward remediating the vulnerability.
Alternatively, organizations with an effective dependency mapping system can establish most of this information with significantly less effort. Using that system, they can quickly identify any occurrences of the vulnerable connector and then the existence of any mitigating measures. When specific information is needed from engineering teams, targeted questions can be asked, shortening the response time.
Optimize the vulnerability management lifecycle
General vulnerability management typically uses a six-stage process for taking a vulnerability from identification to remediation. Each of these stages has specific actions that move a vulnerability from a generic “this could be a problem with our platform” through to “here is the person or team responsible for getting it fixed and here is how we will confirm this.”
Sitting over all of these steps is the organization’s overall management of this vulnerability lifecycle. There are two key ways to optimize this management.
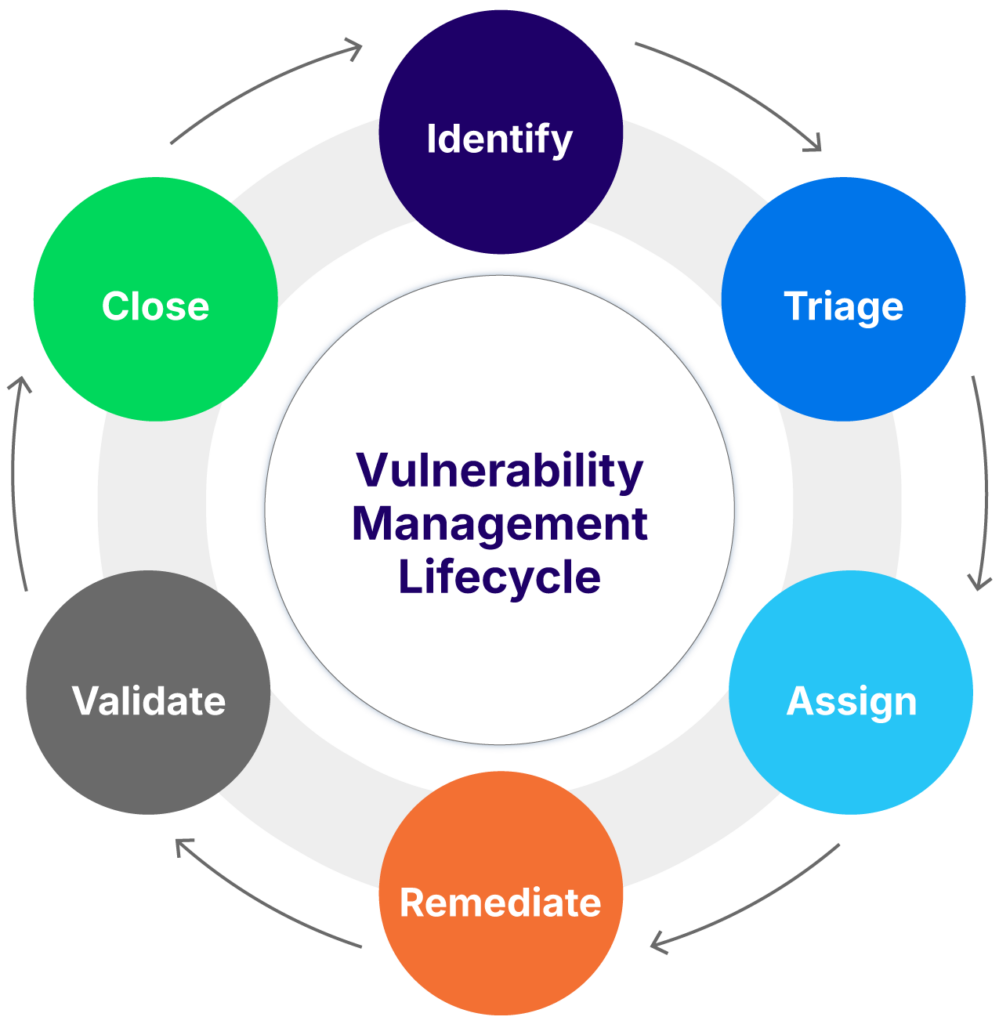
The vulnerability management lifecycle (source)
Reduce manual overhead
Step one in any organization’s vulnerability management lifecycle is to reduce manual overhead wherever and whenever possible. For example, there is absolutely no benefit in having human cognitive resources manually copy and paste critical technical information from their vulnerability management program to their JIRA instance for task management. In fact, there are significant downsides to this approach, not least of which is the opportunity for copy-and-paste errors.
Instead, adopt an automation-first mindset for your vulnerability management program. Ensure that your asset discovery program automatically integrates with your CMDB. Make sure that your infrastructure team automatically integrates any infrastructure updates to your CMDB, removing any need for someone to remember to update a random spreadsheet somewhere. Take time to make sure that when any of the above changes happen, there is an automatic process in place to re-map previous dependency graphs.
Each of these steps may take a little bit of time up front, but the payoff is huge.
Match testing environments with production environments
There is nothing more frustrating for vulnerability management teams than deploying a critical remediation patch that worked perfectly fine in their testing environments only to crash the production environment completely. It degrades trust in them as a capability and causes chaos throughout the organization.
It is also completely unnecessary.
To illustrate this point, let’s consider a fairly standard implementation of a patch-deployment process. Most organizations and teams inherently understand how this should happen. Just like with code deployments, they have some kind of staged release process that includes a testing environment, deployment to a low-risk production environment, and so on, until the patch is rolled out. Along the way, they create opportunities for rollbacks and retries, providing on and off ramps to mitigate any critical business-impacting failures. So far, so good.
However, most organizations fail to consider the essential connection between their testing and production environments. In an effort to save resources, and because replicating a true production environment is ‘hard’, they choose lightweight representative environments with only the minimum amount of resources and dependencies to make their deployment pipelines work.
Then, a high-pressure, time-sensitive deployment turns up. Suddenly, organizations can’t afford to wait 48 hours for a critical patch deployment decision cycle to happen. Teams don’t have time to slowly roll out a patch when sensitive customer information is at risk due to a zero-day vulnerability that is being actively exploited.
Suddenly, that ‘representative environment’ becomes a liability. Without the ability to test the urgent patch in an environment that exactly matches its target destination, teams are unable to guarantee its reliability.
Mature vulnerability management programs mitigate this risk by ensuring that their testing and production environments are identical. Leveraging continuously updated CMDBs, they ensure that every package, patch, and third-party library is exactly replicated. The only difference between the two environments is that one holds real customer-serving information and the other does not.
Doing this makes the vulnerability management processes significantly more effective. Vulnerabilities, including system patches, can be deployed rapidly and safely. Any remediation activities will consider all system dependencies and potential downstream impacts. Teams have a high level of confidence that if the patch works in their testing environment, it will work in the production environment.
Choose an effective set of measures
The truism that “what can be measured can be improved” applies just as much to vulnerability management as to any other area. The process improvements and vulnerability management best practices described in this article only make sense when they lead to a measurable improvement in an organization’s risk posture. This is only possible when organizations have a detailed understanding of their environments and can measure the impact of the best practices being recommended.
Traditional vulnerability metrics often focus on arbitrary measurements that lack correlation with an organization’s overall vulnerability risk. For instance, knowing that an organization has 50% fewer vulnerabilities this year than last year means nothing if this year’s vulnerabilities led to more exploitation. Similarly, measuring mean time to respond (MTTR) is pretty pointless if the overall MTTR goes down but, as a result, the MTTR of business-impacting vulnerabilities goes up.
A more effective approach is to develop a well-rounded set of metrics and apply them to your environment’s various asset classes. This way, each team can report small, measurable improvements for the assets they are responsible for, which reduces the organization’s overall risk. Along the way, you’ll have a far deeper understanding of what is working and what is not within your vulnerability management program.
Here are the steps you need to take:
- Develop a useful set of metrics.
- Apply metrics to each asset class.
- Measure each asset class individually.
Develop a useful set of metrics
Start by developing a set of metrics that make sense in the context of your organization. These metrics should provide supporting coverage centred on a specific theme.
For instance, imagine that you want to understand the efficacy of your vulnerability identification program. To do this, you could use metrics such as scan coverage, false positive rate, and mean time to detect. Alternatively, if you wanted to focus on how effective your patching program is, you might choose patch status, mean-time-to-remediation, and rate-of-recurrence.
The table below describes helpful metrics that cover a variety of situations.
| Metric | Measures | Example |
|---|---|---|
| Scan coverage | The percentage of known assets scanned for vulnerabilities. | 85% of the network has been scanned for vulnerability to the EternalBlue exploit. |
| False positive rate | The number of vulnerabilities reported by automated systems (i.e., scanners) that turn out to be incorrect. | 5% of the vulnerabilities reported by tool X do not exist in the system. |
| Patch status | The percentage of known vulnerabilities that have been patched in the system. | 100% of critical vulnerabilities in the system have been patched, and 85% of low-severity vulnerabilities have been patched. |
| Rate of recurrence | The percentage of previously remediated vulnerabilities that reappear. | 1% of the systems patched for EternalBlue became vulnerable again in one month’s time. |
| Mean time to detect | The average time to detect a vulnerability after it has been introduced to the system. Note that some organizations will differentiate between third-party vulnerabilities (e.g., in Windows) vs. their own source code. | It takes 90 days to detect a new vulnerability. |
| Mean time to remediation | The average time for a vulnerability to be remediated after discovery. This should be broken down by severity and asset type. | It takes 48 hours to remediate a critical vulnerability on SQL servers. |
| Code coverage | The amount of an organization’s source code covered by automated tools such as static application security testing (SAST) and dynamic application security testing (DAST). This should be further broken down into repositories and applications. | 70% of the functions in application X are covered by SAST. 95% of the functionality for application Y is tested automatically once deployed into production. |
| Discovery method | How different vulnerabilities are found. Ideally an organization finds these themselves rather than relying on a bug-bounty program. | 99% of all critical vulnerabilities were found by the internal testing team. |
Increase specificity across assets
Most organizations have certain assets that are more business-critical than others. Even though the measurement system you developed in the previous section might remain the same, you may not want the measurement outcomes to be the same. Typically, most organizations want to patch business-critical vulnerabilities faster than out-of-the-way development environments with no business impact.
To do this, apply your measurement system to specific teams and asset classes within your organization. You can divide this any way that makes sense within your organization; just be careful not to mix high-impact assets with low-impact assets.
Track improvements over time
The final step in this section is somewhat obvious but worth emphasizing. As with any new business process or application, the true value of tracking changes is their improvement over time. No matter where you start on this journey, consistently improving your metrics over time will have the greatest impact on risk reduction for your organization.
Last thoughts
From reactive patching to proactive risk reduction, vulnerability management is a continuously evolving practice that all organizations must adopt. Doing so requires organizations to shift how they approach cybersecurity.
Instead of using static, theoretical vulnerability scoring methods like CVSS, organizations that want to win in this space adopt a posture of business-aligned and asset-informed risk assessment. Doing so enables them to achieve security outcomes that reduce their overall risk while maintaining operational efficiency. Even more importantly, they can measure this change, which allows them to build momentum over time.
As threats continue, organizations need to master a contextual vulnerability management program that allows them to be agile while preserving the security of their critical assets and maintaining customer trust.