Device42 Webinar with Forrester Research – Top 5 Reasons CMDBs Fail: How To Turn Them into Success
Video Transcript
Configuration Management Databases (CMDBs) are a repository, cataloging and storing all Configuration Items (CI’s) that have been identified as important IT infrastructure. CMDBs have been an ITIL practice since the 1980’s, and are still just as relevant today; however, with new advanced technologies such as virtualization, and containerization, CMDBs have become more complex than ever, and many businesses simply fail to implement them.
Join us as Charles Betz explains why so many companies struggle with there CMDB, and how you can avoid their common pitfalls. – Presentation followed by an indepth look at Device42, with a product demo by Jesse Long.
Host (Parker Hathcock): Right now i’d like to introduce our presenters. Our guest speaker Charles Betz is a Principal Analyst from Forrester Research. Charles is a leading researcher in the Infrastructure and Operations space at Forrester and his coverage includes application discovery and dependency mapping, configuration management, and the configuration management database or the CMDB which will be the topic of today. He’s going to be sharing his thoughts on the reasons CMDB’s fail but still why the data they attempt to provide is only becoming more important in the modern hybrid enterprise. It’s also my pleasure to introduce Jesse Long Solutions Architect with Device 42. After Charles’ presentation Jesse will provide a brief but powerful demo of Device 42 and how it overcomes a lot of the reasons CMDB’s fail. Thanks to both of you and take it away, Charlie.
Charles Betz: Thank you Parker and it’s my pleasure and honor to be here today with Device 42 talking about this very important topic. I’ve been involved with CMDBs since about I think the year 2003 or so was when I first heard this notorious four-letter acronym and they have been a part of the conversation fairly consistently since then and continue to be an important part of the conversation around IT management. Often with quite a bit of skepticism, because CMDBs are hard and they fail. So we have kind of a growing dread or this common sense in the industry of hopelessness as it says here “abandon all hope ye who enter here”. I think this is a quote from dante’s inferno and if you’re not careful this can too easily be the main feeling you have as you start to embark on your CMDB journey.
Charles: So let’s talk a little bit about why we need them and what the goal and the vision has been. We have a lot of tech and the tech is sometimes well organized and sometimes it appears a little bit less well organized. We see both on this slide and understanding what the tech is doing, why it’s important, why is it there, why is this particular server in that rack you know, why is that in the you know rack unit 20? What’s it doing, what’s the data on it’s hard drive and who owns that data? Who cares? Are there compliance issues? What are the operational issues? And so on, and so forth. Obviously to manage complexity you have to have a picture of the complexity and that’s been the grand vision of the CMDB both to provide the high level macro vision and macro structure of your IT estate including how it’s interacting even across countries or continents as well as providing the micro-level insight into particular configurations and particular choices with particular parameters, that may or may not be set in a given way, on a given device, in a given location. All of the ripple effects up and down the chain that come from activities at either level of scale.
Charles: It is a grand vision, it is very hard to achieve but ultimately and this is why we see so many chief information security officers taking significant interest in the CMDB, “you can’t protect what you don’t see”. You know you are stuck. You’re operating in the dark and without that visibility, your ability to govern your organization and its critical digital assets is limited. But too often CMDBs are literally a dumpster fire. We have many, many cases of failed CMDBs. I’ll have you know I have something of a privileged role as a Forrester Analyst. I talk with CMDB and discovery tool Product Managers across the industry. It is part of my job to know them and know who they are at a wide variety of vendors, and they all hear the stories from the customers.
CMDB failures, data quality death spirals, process concerns, scoping concerns, architecture concerns, and ultimately CMDBs that have become money pits and organizations that literally say “we have tried CMDBs three times now and we’re trying it a fourth time and we’re really hoping we get it right this time”. I’m not exaggerating, that’s a real conversation I’ve had with a very large financial services organization.
Charles: How do they fail? Well they fail because the data in them can’t be trusted, they fail because they’re no longer relevant, they’re not tracking the modern digital resources that are coming online. They fail because people think you can buy a CMDB, and it’s not a matter of just buying one you have to actually operate it. They fail because the data latency doesn’t meet the business needs and they fail because there is not a clear concept of process. There is not quality management at the process level as well as at the data level and ultimately I translate all of these into three major more abstract if you will points. Lack of alignment to organizational objectives, lack of an economic model, and lack of data governance. These are the areas that i’ll go into.
Charles: Data quality, this is probably the biggest risk. We see multiple accounts in the industry, you know the CMDB started to develop a bad reputation, people stopped using it. They wound up creating shadow systems, those shadow systems also had data issues, we wound up with a proliferation of shadow systems that nobody trusted, and the central CMDB nobody trusted, and things just spiraled downward from there. This story is all too common in the industry.
Charles: Kubernetes you know? Can your CMDB handle Kubernetes? Most of them are just starting to come online with Kubernetes functionality even virtual machines pose their own set of challenges. There are still too many CMDBs – when I’m being presented with the organization’s implementation of a CMDB they’re fixated on physical bare metal devices at best, and they do not understand the logical architecture, they don’t understand the virtual architecture, and they don’t understand the service architecture. They’re just basically asset registries. This is problematic because so much of what the CMDB can do for you really starts to add value when you actually strive to get to these more sophisticated, and more current technological concerns and capabilities.
Charles: A hungry cat, this cat is starved for OPEX. We see all too often the CMDB is approved as a two million dollar line item in the capital budget for implementation as a project in a given year and it’s like pulling teeth and sometimes not even possible to get the necessary head-count to run the thing. “Oh we thought that it would just run itself” it doesn’t run itself you have to have operational resources devoted to your CMDB. Otherwise my recommendation in general is don’t even try.
Charles: Manual maintenance refresh cycles that don’t meet business needs, they’re too slow and so people start to not trust it because latency is perceived to be an issue. Tightly coupled to that issue is just bad process, messy concepts of you know well okay we’re running various discovery and alignment reconciliation processes and that’s all great but what do we do with the exceptions that pop out of the processes. Do we have again some operational individual who is looking at the reconciliations? At the delta reports? At the different exceptions that are being produced by discovery tooling? And then saying well what are we going to do about this, and what does this mean? What does this imply? Do we need to consider whether there’s a gap in the process somewhere? All of these things are what we see in day in and day out as we talk to organizations who are struggling with CMDBs and again to repeat myself they all start to have certain things in common. The fact that the concept of the CMDB is not well aligned to organizational objectives. it doesn’t have a rational economic model, and data governance has been overlooked. So let’s for example look at the issue, the fundamental issue of currency and alignment to the organizational model.
Charles: More modern organizations that maybe pride themselves on being agile being cloud native. They might come in very skeptical of the CMDB, they may say well we’re all in the cloud, why do we need a CMDB? My response to that is, you always have an information management problem along your digital pipeline. You can eliminate the word CMDB from your vocabulary, you can take the position that CMDB is this old-fashioned idea, something my Dad did but you still have an information management problem and you’re still on the hook for that information. It never goes away. You have to be accountable for what you ran, where, when, and how it was built. What the dependencies are, what your inventories are, otherwise how do you provide any kind of assurance that for example you’re handling people’s data securely? If you’re not managing the information, you can’t provide the assurance. You don’t have visibility into what depends on what and you are going to have issues as you try to resolve incidents. You know whether they’re security incidents or operational incidents, you’re going to struggle in managing your portfolio investments. The list goes on.
Charles: Ultimately the configuration management database is an economic proposition. Again ignore the word CMDB, if you like but if you have no information you are going to continually recollect the information. This is sometimes termed a data call and this is when the notorious spreadsheet goes out by an email and somebody who’s in a position where you can’t say no to them says please take three hours of your day and fill this spreadsheet out because we don’t know what we have and who’s responsible for it. On the other side, you have the problem of trying to achieve perfection in the CMDB which can result in its own set of costs and data quality assurance, both in terms of collecting and assuring quality of the data as well as if you are imposing any kind of process delays in the interest of getting the data. If you’re telling people you can’t move forward until the CMDB is up to date, which is sometimes necessary but it’s a risky proposition sometimes to block progress just because data’s not been updated. Ultimately you have to seek a balance of what you want your costs to be – less than your benefits and you need to understand your benefits in terms of the CMDB is helping you adapt your systems with greater agility. It’s helping you manage the costs of your systems for greater efficiency and it’s helping reduce the risk that you’re running your digital systems, in your digital architecture, the CMDB.
Charles: The economic case for the CMDB ultimately needs to be expressed in those three terms. Top-line, bottom-line, and risk. Ultimately you are on the hook for important information and this is back to the point about cloud native people will say to me we’re running Kubernetes and Docker why do we need a CMDB? And I say “well i’m not hung up on the four-letter acronym CMDB, but you just ran a container with an unpatched version of Apache Struts, and that container also had commercial software in it, that resulted in license consumption”. You’re on the hook for all of that and whether you put it in a logging tool or in a CMDB, or you take it from the logging tool and you distill some of it into the CMDB, you have the information management problem that leads us to a conversation around data governance.
Charles: This is probably the most important slide I have to offer many of you here today (Slide details the importance of data governance with a flow chart of quality requirements, policies, quality risks and controls, processes, audits, exceptions, findings and corrective actions) because many people who understand CMDB, they come from the operations side of the house they come from the service management side of the house. Life is short, it’s hard to understand the breadth and the scope of the professional world we’re in but I talked to way too many people who run CMDBs who do not know that the data management association even exists. And yet you’re running a database, well database and data management are significant areas of professional practice people spend their whole careers there, and yes there’s a body of knowledge that deals with all of the things that CMDB is for data management, data quality, data assurance, data governance, data modeling, all of the relationship of data to process. All of these things are covered in the data management body of knowledge and I urge any of you with operational responsibilities for a CMDB today to acquire a copy of the data management body of knowledge. In part it will explain to you the basic fundamental premises of data governance and how your economic model drives quality requirements. That then should be translated into policies that are in part controls for various risks and how you test with audits and exception reporting out of processes. Processes also are forms of controls and we both run the process to keep the data updated as well as we run it to generate exceptions out of both your audit findings, and the exceptions coming from your processes. You then take corrective actions to fix the data, and two, fix the reason why it was inaccurate in the first place. This is data quality in a nutshell and there are great consultants out there, and again people who’ve spent their whole lives consulting and advising just on this topic, and if you’ve got a CMDB where you’re struggling with these things I encourage you to reach out in your organization. You may find that you have a data management group who you’ve never even heard of, and you’ll explain your problems to them and they’ll nod their heads and they will say, “yes this sounds familiar” because this is something that they deal with in business facing databases all the time.
Charles: You need to have a good data model and yet the data model is not easy.
It can be too simple and then it doesn’t give you the richness you need to solve your problems. It can be too complicated and then you have maintenance issues again you have the economic problem that shows up in the data model and this is, where again having the advice of a qualified professional is important. I will warn you and I have fallen into this trap. In my own career I would err on the side of too simple and then gradually increase the complexity. It does not work to create a model that is too complex. If you start with a heavy waterfall, thinking we’re going to look at all of the requirements for the CMDB, we’re going to bring all the data requirements together, and then we’re going to create the perfect data model for the CMDB. That is a very risky scenario, I have seen it not work because it’s easy to create a complicated data model. It’s much harder to figure out the process by which you keep it maintained with clean high quality data, and the process, and the data model needed to involve simultaneously and it’s really tempting to go off and create that complicated schema and leave the process to something that will happen later. Do not do that please.
Charles: I want to talk a little bit, as I conclude about some of the common misunderstandings and scoping of CMDB and some of the architecture. Some of the fundamental conceptual architecture. So one of the most important things to remember is that the CMDB does not do configuration management. That might be a puzzling statement but configuration management at the element level, if i’m looking at the bits and bytes on the settings on something like my cell phone here that’s a level of detail that we generally don’t want in a CMDB and nor does the CMDB have the ability to go out to the managed element and actually interact with it and tweak its bits and bytes, and tweak its settings. The CMDBs don’t do that, they’re passively scanned, they bring back information but they don’t push configuration out. For mobile devices that’s applications like Mobile Iron that was bought by Avanti or Jamf that specializes in Mac
- For production servers, we use things like Ansible, Bladelogic, Salt Stack, Chef and Puppet, that is what is meant by configuration management to significant portions of the industry. The CMDB does service configuration management, which is the problem of inventories and dependencies. We also have software configuration management which is the domain of repositories. We also see a significant overlap between software and element
configuration management in the guise of infrastructure is code and release automation.
These are topics I will talk about in different contexts but not so much today.
Charles: The key message here is be clear on what domain you’re in. If people try to engage you in a conversation about configuration management and there has been a lot of problems with people confusing configuration management, including auditors and regulators confusing service and element configuration management. That was a real problem about 15 years ago that I had to work on quite a bit when I was in financial services. Because the regulators would come in and assume that the CMDB was storing all this low-level data, that it was completely inappropriate for. Ultimately I like to use the four-lifecycle model for a CMDB. It should be able to give you visibility into your technologies so this is your generic products you’re running, we’re running Oracle X or you know we have Macbook Airs. The assets which is the specific serial numbers and entitlements of the products, the platforms like the shared database platform, the shared services platforms, and then the applications running on top of them. This is a good framing for a basic CMDB and at the element and asset layer we have discovery. So we have basic and this what my good friends from Device 42 we’ll talk more about as I wrap up here we have the different ways that data can be discovered from non credentialed network scans through credentialed, agentless interrogations to based. And then there are emerging alternatives around netflow based discovery apm tools, open telemetry, even the enhanced Berkeley packet filter is starting to show up in some of these conversations. So this is an area where there’s quite a bit of innovation happening and yet there are some basic kinds of common themes that we see as we look at this space. “One of the most important aspects of course is to maintain a clear distinction in your architecture between the data that you have to declare versus the data that is discoverable. And, that all important overlap in between.” You can’t discover the long name or the business description of a system, you can discover the technical resources and the element configurations and you can tie the two together with tagging and fingerprinting this is again a critical conceptual architecture for you to bear in mind and the center overlapping area. It’s critical master data you’re all going to go get a copy of the dp box and read a section on master data management right because this is the critical master data.
Charles: You have to manage in this space and as we look forward we can see that there are increasingly new challenges coming online. Virtual has been a challenge for CMDBs for some time but cloud native is still an unsolved problem in many cases as well as containers. We have for every server that’s going into the cloud we’ve got 10 devices showing up on the edge with IoT. Devops, the increasing speed of releases and the relationship of the core devops.
The source control repository, the package manager, and the relationships of those to the traditional CMDB are very interesting. And of course increasing levels of open source in the environment challenge.
Charles: From the software asset management perspective there are many, many related topics we don’t have time to discuss today. I will close with this basic architecture slide (slide shows the interdependencies of the CMDB – including on prem, repositories, CD tools, logs, portfolios, change and incident management and more) at a super high level. But I would encourage you all to be thinking in terms of an integrated architecture for your business of IT. I’ve written extensively on this and one the topics I have a book out there on amazon, architecture and patterns for it, I went very deeply into these problems frameworks like IT for IT also talk about this but I think it’s super important to understand what your systems of record are for the major data topics that you’re managing in your IT control plane, in your digital control plane, and what is the system ultimately that manages your systems. How does that system relate to other systems and capabilities? As I look ahead I see a lot more AI on the horizon. I see AI and Machine Learning. I see the rise of semi-autonomous product teams that increasingly are looking for the CMDB to provide critical information for their management objectives. We’re seeing increasingly robust interfaces between application performance management for example and traditional CMDBs and ultimately a much more integrated IT data fabric.
It would be nice if we would change the name CMDB, it’s not the best name because it’s not just a database, it’s a set of data capabilities that need to interoperate. But for right now the word CMDB is very much present and center in our discussions today and it’s with that final observation that I’m gonna hand this on to Jesse who’s going or I’m going back to Parker perhaps who will then present Device 42’s offerings and point of view on this space.
Parker: Thank you very much Charlie. I was just going to introduce Jesse again, Jesse’s going to show how Device 42 offers a single source of truth for IT to solve a lot of these problems and provide that background, that basis for the data fabric that is needed in the modern enterprise. Jesse, I think you’ve got a really powerful presentation of our demonstration of our product today.
Jesse Long: Okay, perfect so everybody can hear me okay and see my screen? Okay perfect, alright well i’ll just get right into this then so, you know Device 42 is a complete agentless discovery. We can provide an agent for things like laptops or things that move around on a network or don’t sit on your network. We take an approach of deploying a virtual appliance or a vm into your environment so your modern hypervisor will deploy it. Once we have that deployed you give that vm an IP address. You browse that IP and just like that you’re doing discovery. First thing you see will be this dashboard (shows a demo of the Device 42 dashboard). You can log in as a local admin or a local user. You can use Active Directory to get to it. It’s all role-based access so who has access to what, but i’ll kind of just get right into it. So it starts with discovery, so that’s where we’re going to get at the information or what we’re trying to discover. We talked about an agent-based scan, that’s where we can come in and say “hey I want to push this out to all of my laptops, you know I don’t really know what they’re doing, they’re kind of sitting remotely in their homes or wherever they may be”. So we can push those out to you via group policy or scripting or other types of discovery such as,certificate discovery, cloud discovery, hypervisor, mixed windows, more of the physical side so SNMP, storage arrays, we can look directly into your storage and tell you how it’s performing. How the storage is communicating to other devices, how it’s made up of things like that and then UCS load balancers, things like that as well. All of these are going to have sub platforms so I’ll open up a hypervisor nix windows just to show you how we do discovery.
Jesse: So it’s really five things that we need for discovery. It’s creating a name of the job. It’s the platform which we’re discovering. You can see next is going to use port 22. Windows would use WMI ports. A lot of these will be API driven but then it’s what you are discovering so you know a subnet, multiple subnets, a range of IP addresses, and host names as long as a remote collector has access. So a remote collector is just a skin version of our main appliance. The remote collector will go out there and do the discovery, sending the information back to the main appliance via port 443. That’s where we help scale these larger environments. You don’t have to poke holes in the firewall, these are collecting the information and sending it back to the main appliance. Then we create a read-only credential, we say “okay well now that we’re on this machine, we saw that port 22 is open. Let’s use this read-only credential to kind of see what’s happening in that environment, with running those common protocols.” And, then lastly we create a schedule to say “how often do you want to sample this data to see changes that are happening within the environment”? But once these run we give you a discovery score to tell you what we discovered and what we were not able to discover because of credential issues or or whatnot but once that happens it becomes a device in Device 42. So here’s an example of a device.
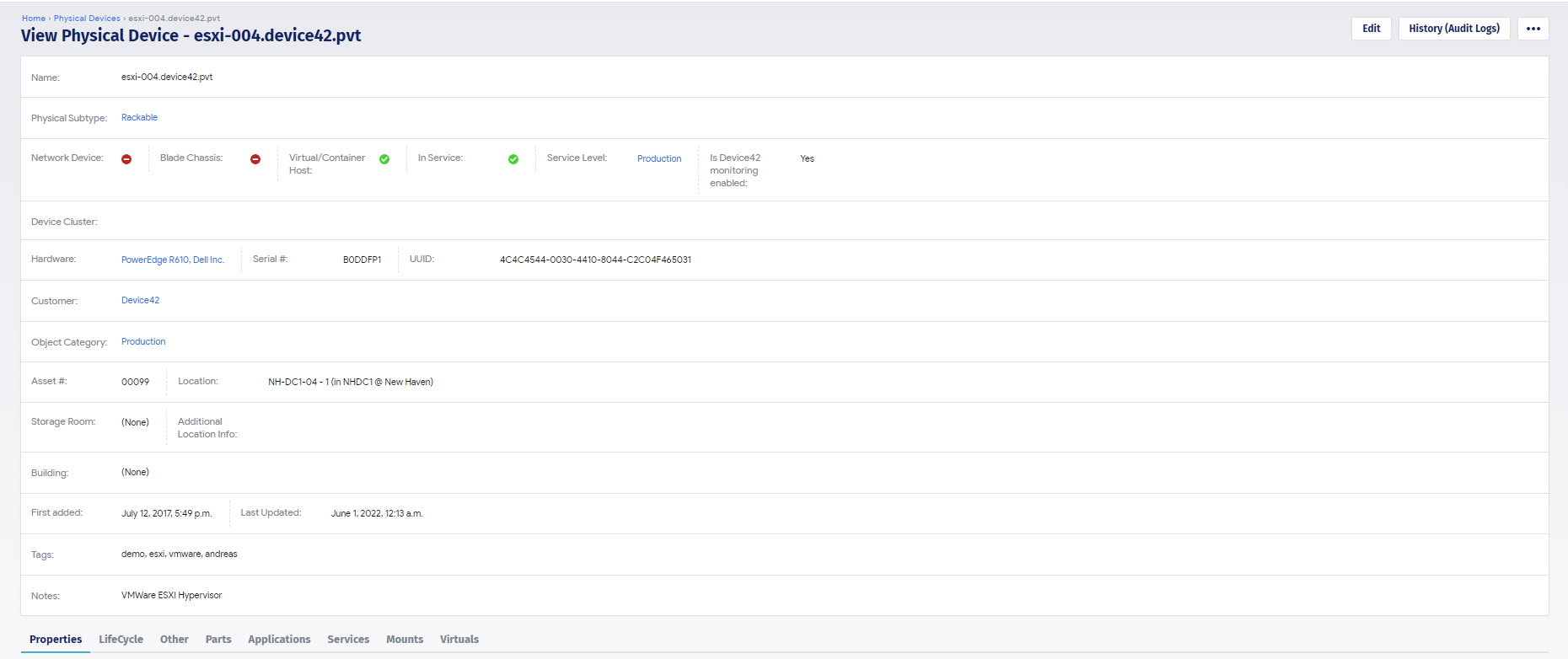
This is a physical device you can see we’re discovering the host name, and what type of device it is. It’s a virtual host. We can see if it’s part of a cluster, hardware serial UUID, and we can do things with this information. For instance we can do a warranty sync to push this out to all the major vendors and the vendors will come back and say “hey yeah we do have support for this, this is the type of support we have, this is when it starts, and this is when it ends”. So it’s an example of not only that we’re collecting the information, but it’s what we do with it once we have it. We can create more categorizing information at the create a job creation or after the fact where it’s physically located which I’ll talk about here in a bit. Then briefly i’ll talk about the properties of the machine, so CPUS, cores per CPU, memory things like that. That’s a summary of what we’re discovering. We can look at parts and see what’s physically attached, deep socket, dim power supplies, NICs things like that as well. We can see operating systems so we’re seeing the OS version, the build, the rack information connectivity. We’re looking at MAC tables, ARC tables, IP tables, so we’re able to tell the story of a MAC address and where it’s talking through a specific NIC through a port, through a VLAN, to a port on this switch. I can show you that here in a bit as well but back to the rack.
Jesse: To tell the story of everything that Device 42 does, we can start from a rack. So if we look at a rack we can see these devices that are living inside this rack. We can interact with these so we can say “okay here’s a top of rack switch, let me look at an impact chart to see what kind of physical connectivity is happening around here that we can see.” This is all interactive so we can expand on things as well here. 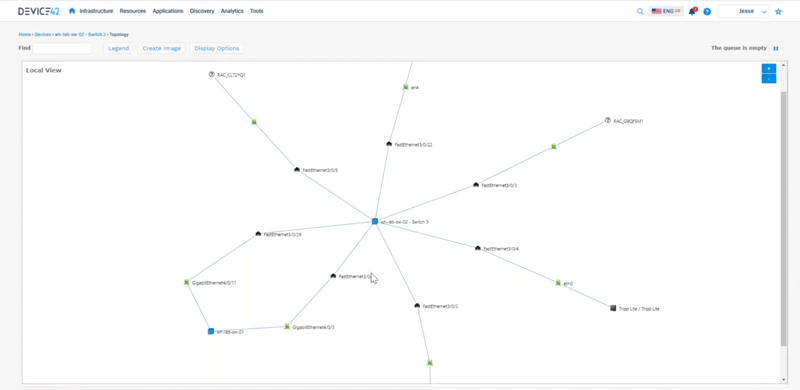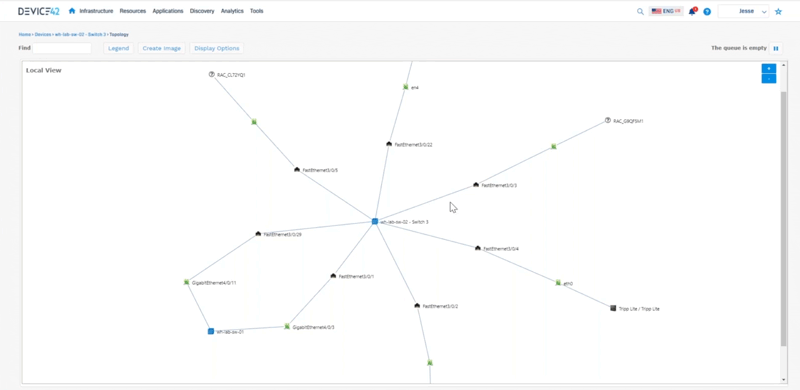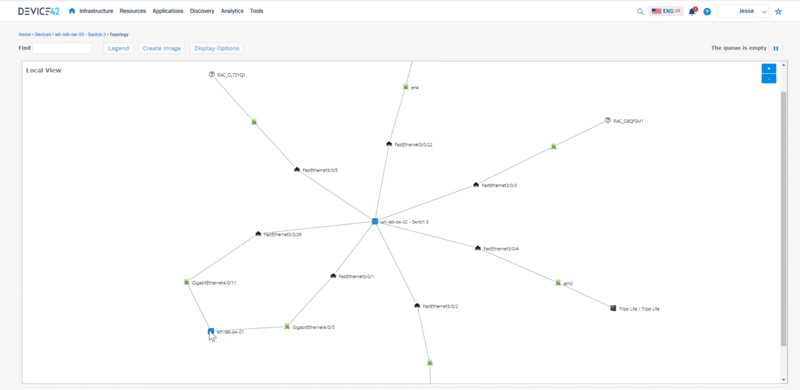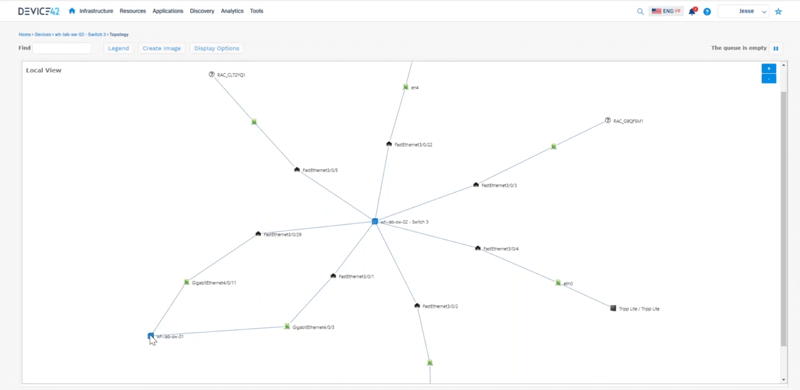
We can go back to kind of a bird’s eye view of a room, so we can say “okay here’s a room that, or a rack that doesn’t have a lot of devices in it. Here’s something that has a little bit more, here’s a device that’s full,’’ so we can look at the power consumption and things like that as well. We can go directly from here and say “okay here’s a host let me look at a host inside of that host”, we can see things like the virtual machines that are living on that host, we can pick out you know MySQL server and say “okay here’s here’s a vm” – we can see the host name, here we can see where that’s living, we can see what’s allocated to it, the operating system information, connectivity, etc. The biggest takeaways are now we can start to look at software that’s installed on this machine, versioning things like that as well. We can look at the services that are communicating. We can also look at the resource utilization, so we can help you right size for how much that device is actually being used. Are you over utilizing your cpu, memory, disks, networking? Then we can also look at that service communication, so that’s where we start to build out the application dependency mapping. We can look at that topology here and tell you all the things that are talking to that device. So you can see this MySQL server on the left hand side.
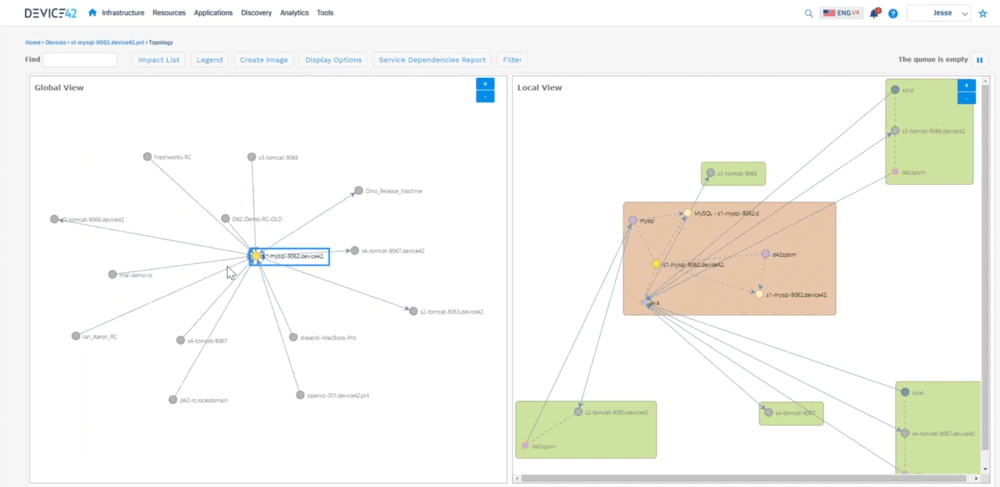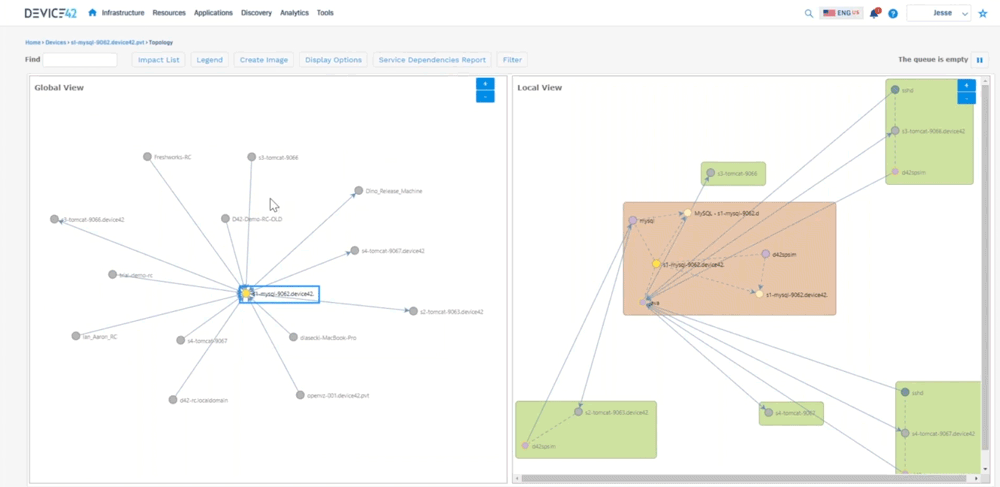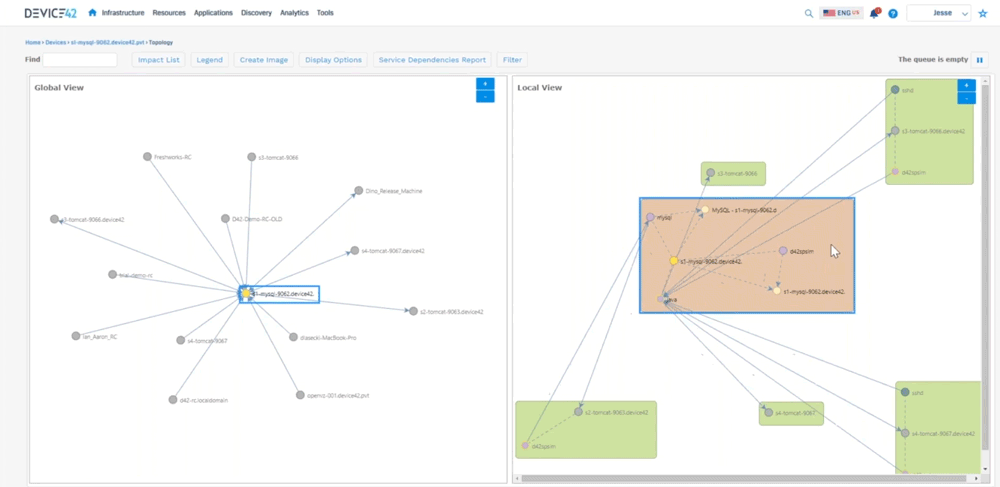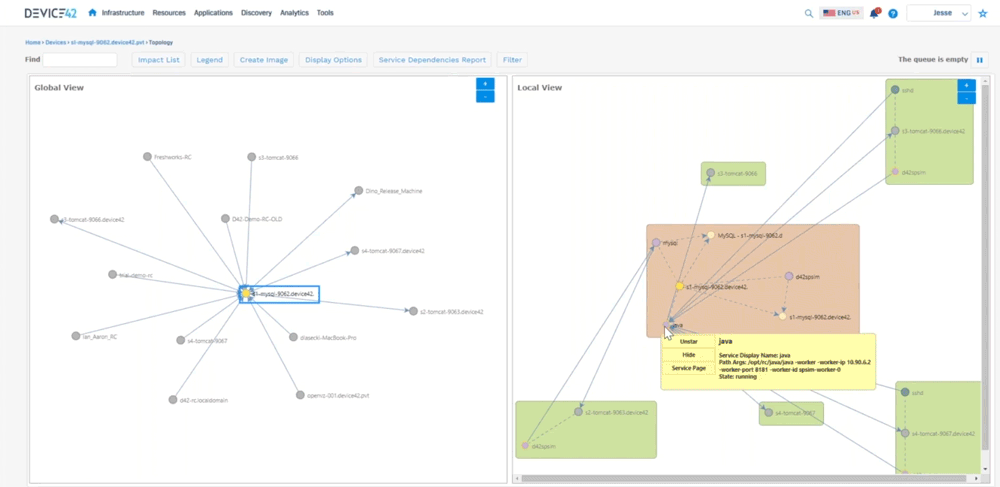
All the devices talking on the right hand side (shows a local view of interconnected devices) you can see how they’re communicating, so you can see you know java’s busy talking to a lot of different devices. You can see the worker IPs, worker ports, we automatically hide hidden services, because we don’t want to show all that ssh communication we can filter out some of that. This can get very busy because again it’s looking at all service communication.
Jesse: Device 42 created what we call an affinity group so you get into that application dependency mapping. We take out the noise, and then we expand relationships if they are application relevant to where we can say “okay here’s this MySQL server it’s talking to this Apache server”, and you can see the direction that’s sending information down to tomcat, you can see the type of communication it’s sending, and then tomcat sending information here, so we’re able to see all that communication as in regards to an application. What this does not show is you what is this application or what do these components do. There’s two different kinds of sides to this. There’s this Apache server up here, there’s one down here, maybe one is your development side, and one is production and it’s sharing a database. Well how do we call that out? So that’s where we created business applications. So we can create these things and say “who’s the owner of this? Who’s the business owner? Is it mission critical? Is it part of a migration wave? What are the application or the devices that make up this application?” What are the application components? And then really what we get to is where we can create a screen that looks like this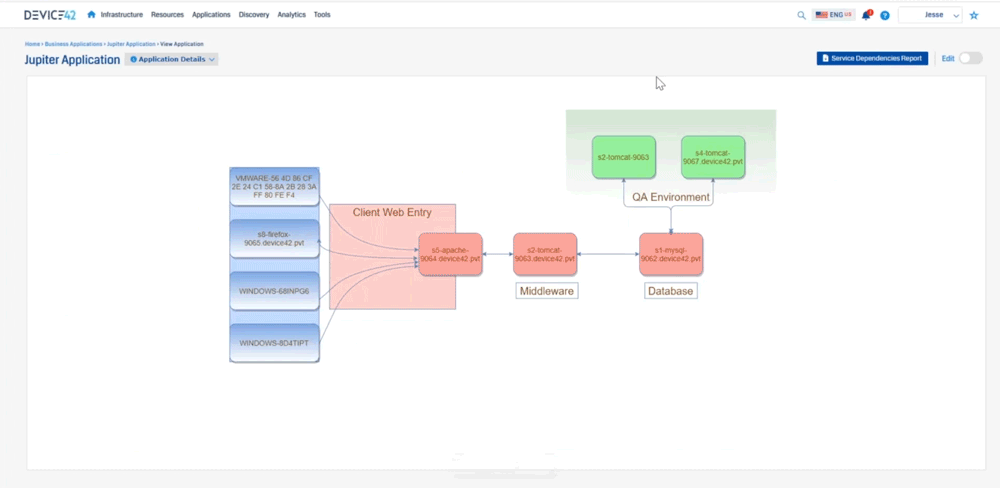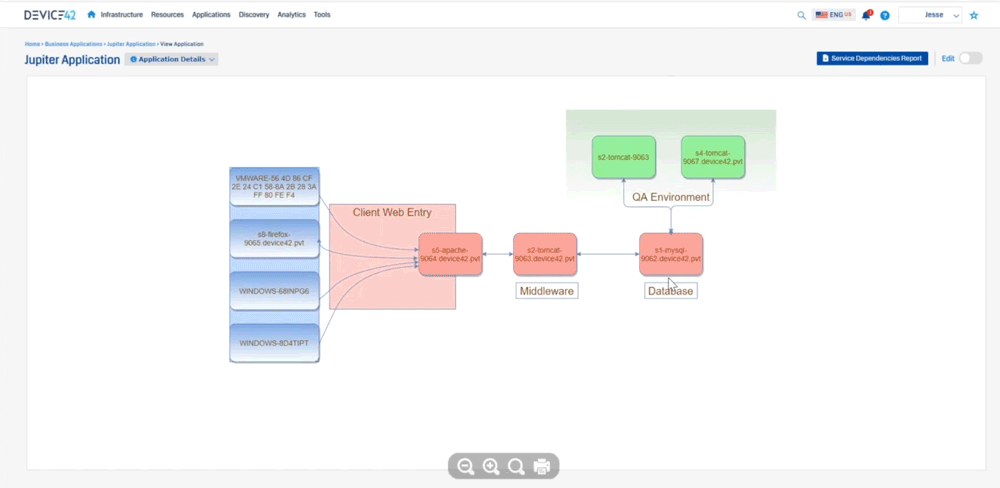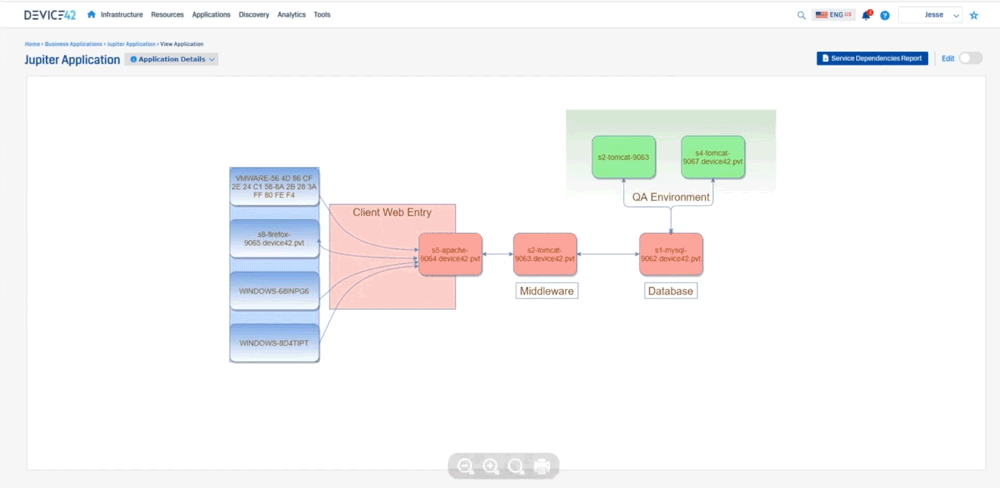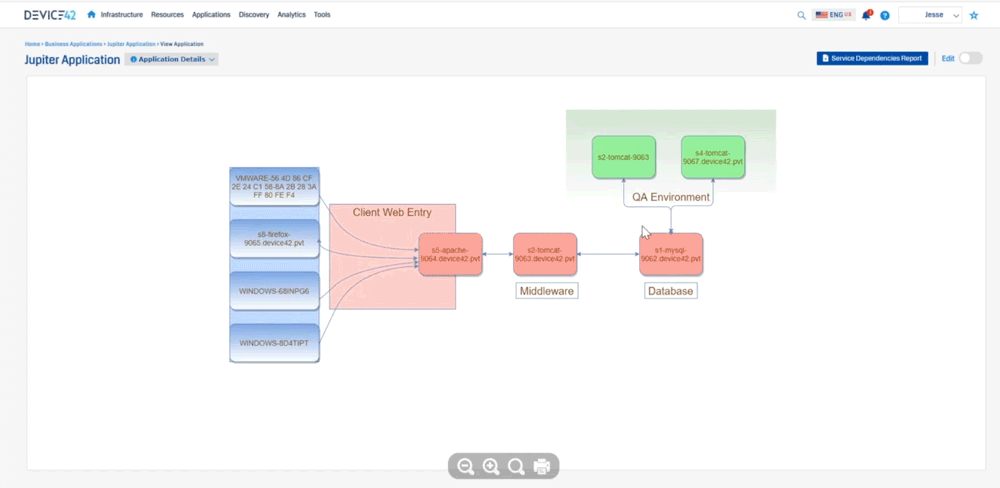
it’s more consumable to say “hey we have our database layer, our middleware layer, we have our client entry, and then we have a qa environment and we’re really just getting at that via importing in that affinity group. We’re importing in this data here and then we’re able to kind of create that relationship so that’s a lot of information.
Jesse: Device 42 does a lot more as far as looking at the IPAM side of Device 42. I talked about the storage arrays, database information, containerization. We’re seeing a lot of all of this certificate management. Device 42 does a really good job and makes it very easy to discover all of this information, and then it’s kind of an okay now what? So what are we going to do with this data so Device 42 has a lot of out of the box type reporting that you can use. We have an object query language that’s built into Device 42 so you can take data out and consume it how you’d like. We have a lot of integrations, Power BI for instance, so we can take this kind of data and it’s a via an ODBC connection, we can see this real time, grass here that you want to kind of see on this side. Maybe you want to look through your security layer to see how you have commonly explored ports open. You want to look at things like your storage arrays, you have degraded disks, things like that. So you’re able to create these awesome things that you can interact with again. If you wanted to consume the data through Power BI you don’t have to use Device 42. We can push this data out to other CMDBs for instance like ServiceNow. So you can see that same MySQL device on ServiceNow. We’re pushing this information out after we do the discovery using their common import sets. So we’re in their marketplace and we’re getting all the way into looking at the relationships, so we can push those relationships into ServiceNow.
Jessie: That’s about all I have, I’ll leave you with we discover the data very easily, and then we let you consume that however you’d like, including our integrations which you can see here, whether it be Ansible, Puppet, or automation things that Charles was talking about. With that being said, we’re going to push it over to any questions that came up.
Host (Parker Hathcock) That sounds great, thank you very much, that’s a great insight into what we have to offer. I’ve gotten some really good questions in from the audience. Charles could come back and take a look at those questions? Okay this might be a question for Jesse. “Can Device 42 do HW EOL/EOSL, and OS OEL/EOSL for applications?”
Jessie: Yeah, so as everybody knows that’s a moving target, there’s so many different types of end of life and end of service for these hardware or software or OS’s, so because that’s such a moving target Device 42 does show all the different hardware models that we have. We have a place to input in those dates if that’s something that you wanted to do. We have a catalog again because it’s such a moving target sometimes that can get out of date, but we do provide a place to where you can put that information as those changes happen.
Host (Parker): Excellent, excellent. Okay, got another question here for Charles. “How does having seemed to be information support life cycles within my complex hybrid I.T. enterprise?” You touched on this but maybe you could elaborate just a little bit?
Charles: Yeah it’s a great question, and it’s actually related to the previous question because the hardware EOL and EOSL is just a specific aspect of the technology life cycle. I mean we know that technologies they come online you buy them and then eventually you’ve got to get rid of them, Windows 7 went off of support in 2020. So everybody had to then run around figuring out where am I running Windows 7? Oracle, you know oracle versions periodically go through a life cycle, and so if you know what you are running in terms of okay we’ve got a node here that is running Oracle it could be open source, it could be a particular version of Apache Struts but your discovery tools will tell you this and then if your CMDB is well managed, then you understand the services that are depending on that technology and the services for the most part are things that you define. They’re the things that as I talked about, you have to declare because of you it’s difficult for a discovery tool to figure out what the business description of a collection of software is. Device 42 is a great discovery tool but I don’t think you guys would claim that you can do that. So you have to put that in and then you understand “okay well i’ve got you know these services here that are doing these critical digital functions for me and then these are depending on this layer of things that I can discover including these nodes, these devices, these assets, these laptops, these servers, what have you”. Then now I know that I’ve got to go in and I’ve got a touch, and I’ve got to upgrade or maybe patch, because patching is part of the life cycle too. Then that’s going to have the risk of operational impact of these services here or maybe I need to be in a conversation which is never an easy conversation of “hey we’ve got to go from software version x to software version y, Oracle 13 to 15, and guess what we’ve got to budget you know a million dollars to regression across the board”. Typically that’s not welcome news, but it’s news that has to be presented, when you need to upgrade you core infrastructure. If you leave things in that are obsolete eventually they’re not supported by the vendor, and as we all know if it’s not supported by the vendor that means they’re not going to write a security patch, and at that point you’re in an unacceptable security situation.
Host (Parker): Makes sense, alright, another question. “How many people maintain a Device 42 instance?” An example is for a 10,000 employee university serving 30,000 plus students. Jesse?
Jesse: Yeah so Device 42 is all based on scheduling so that’s the good thing about having a CMDB in general but with Device 42 you’re going to be able to create a schedule. Things change. They change all the time. Its devices aren’t just sitting stagnant waiting for you to approve changes. They’re going to change on their own. So that’s where coming in and doing an agentless discovery, and being able see those things change whether it be an environment of 100 devices or 100,000 devices, we’re going to be able to let you know when changes are happening. A lot of times people always ask who’s a competitor of yours and and we always say well Excel is. Because customers think that using Excel is okay.
But it’s as soon as you walk away from that Excel doc, that it’s out of date. So that’s where you do that ongoing discovery. It’s where you’re going to see those changes as they happen.
Charles: I’d like to just jump in on this, because I think that this is a key point that I was also trying to make. It’s so important to have a concept of operations for a tool like Device 42. When you run the discovery you notice that things changed right? But what does that mean to you? What does that mean to your organization? You notice that for example, a device has appeared where there wasn’t one. Well is that something that you expected?
Do you have the process in place to say “ah I expected to see a new device there” because employee provisioning, or a request for change in the configuration or in the service management system, or you’ve been scanning a device and all of a sudden it’s gone. Do you expect that you are checking to see overnight this is what changed, and everything that changed we expected to see. Except here’s three things that we didn’t expect to see, and now this is where you need that operational person that I was mentioning to go chase that stuff down. Because otherwise, you’re taking pictures, but you’re not really acting on the information. I think that, that’s so important to ultimately having long-term success with tools like Device 42 which are super important and super helpful. But they’ve got to be put within the context of an organizational operating model and then they’re really baked in, and they become a valued and accepted part of the enterprise landscape and nobody questions why you’re using them.
Jesse: Yeah and to that point, Device 42 coupled with an ITSM whether it be you JIRA, a service desk, or Zendesk or whatever it may be there, you know when events happen, you know we can make sure there’s ownership to those devices, and we’re making sure that, that’s getting pushed to the right person, so you can be more proactive and not just reactive to events that are happening. It’s not just hey this server went down, let’s create a tier one ticket or tier two ticket or whatever it may be. This is mission critical so this should go up to a tier four ticket whatever it may be there so having that ITSM you know tied into your CMDB is where you see a lot of that success and you’re able to kind of be more reactive there.
Charles Betz – Charles Betz is Forrester’s lead DevOps analyst serving infrastructure and operations professionals globally. In this role, he covers continuous deployment and release automation, incident management, and emerging topics such as containers and chaos engineering. He also covers the transformation of “traditional” IT operations organizations into next-generation digital service organizations. He is also Forrester’s lead analyst for enterprise service management topics such as service portfolio management, service catalog, service desk, NOC, IT asset management, application discovery and dependency mapping, configuration management, and CMDB as well as the intersection of ITSM/ESM and DevOps.