Vulnerability and Patch Management Best Practices
Effective vulnerability and patch management is a proactive approach, not a reactive one. Organizations must minimize threats with forward-thinking strategies and preemptively deploy patches when you discover critical vulnerabilities in the environment. A successful vulnerability and patch management plan requires:
- In-depth knowledge of the organization’s systems
- Collaboration with multiple business functions
- Targeted approaches to reduce risk.
This article reviews the best practices behind implementing a proactive vulnerability and patch management plan. Security professionals can follow these recommendations to stay ahead of attackers and reduce risks.
Summary of vulnerability and patch management best practices
| Best practice | Description |
|---|---|
| Map the attack surface of the organization | The attack surface is where your organization is most vulnerable to threats, whether external-facing services or an untracked asset. Understanding it helps drive vulnerability and patch management efforts. |
| Maintain an accurate Configuration Management Database (CMDB) | An accurate, constantly updated CMDB provides true visibility into the attack surface, including:
|
| Perform risk-based prioritization | Build a list of assets and their associated vulnerabilities. Prioritization of patches is based on their:
|
| Ensure effective communication and integration across cross-platform teams. | Vulnerability and patch management are rarely localized to just one team. Creating a plan that assigns ownership of specific assets with prioritized patching cycles or critical vulnerabilities to those responsible for remediating the vulnerability helps ensure a smooth operation. |
| Automate patch management | Take advantage of repeated processes and tools to mitigate threats more efficiently. |
| Reframe success metrics: measure and report risk reduction | Security progress is measured by risk reduction, not just the number of objects patched. Reframe success metrics to be incremental and measurable. |
The rest of the article discusses these best practices in detail

Discover assets automatically including hardware, software, and cloud infrastructure
Match the assets against your software and hardware license agreements

Comply with your service license needs comprehensively and confidently
Create a plan to understand the attack surface of the organization
The organization’s attack surface is the encompassing area where an unauthorized and malicious user can deny, destroy, or disrupt operational capabilities. It refers to all information or operational assets, like application servers, databases, and network switches.
Vulnerability management helps reduce an organization’s attack surface by proactively mitigating risk so that attackers have fewer footholds to attack and compromise an organization.
However, remediating every vulnerability in the organization is tedious and time-consuming. Not every asset is equal in importance. A plan to identify the organization’s attack surface and which jurisdiction it falls under allows you to prioritize asset patching based on real-world risks.
The techniques below are essential in understanding the attack surface for effective vulnerability and patch management.
Threat modeling
Threat modeling identifies an asset set under scope and potential associated threats. A security engineer or team simulates attack vectors against the system’s architectures and critical assets. The most important takeaway is identifying as many relevant threats the asset can be under as well as any existing countermeasures. There is no one perfect method for threat modeling, though there are many industry-recognized frameworks, such as STRIDE and DREAD, that teams can follow.
For example, a cryptocurrency exchange considers the wallet infrastructure where it handles user private keys as a valuable asset. Therefore, threat modeling would simulate how attackers could steal cryptocurrency or gain access to the private keys by exploiting weaknesses in the wallet infrastructure, then discuss existing countermeasures.
Cyber tabletops
Cyber tabletops utilize threat modeling but incorporate more stakeholders. It is an exercise that guides participants through cybersecurity scenarios they may face and identifies the communication and responses that would arise in those scenarios. When involving relevant stakeholders, you can understand how the organization would respond.
An example exercise would be where participants pretend to be adversaries looking to disrupt the financial services of a particular government website. They propose that the adversaries send phishing emails to deploy malware. The other stakeholders at the table would assess the current security posture. For example
- Are employee machines always patched so that the malware cannot exploit specific vulnerabilities?
- Does another service filter emails, and if so, could the adversaries compromise that email server to let their malware through?
Based on the analysis, they attempt to gauge if the attack would be successful or if there were formal procedures in place that would render the malware moot.
Asset discovery tools
Asset discovery provides a transparent scope view by showing known external advertised IP ranges or web servers in a network. It allows you to perform more accurate threat modeling and cyber tabletops.
Some tools that will allow you to discover assets are listed below:
| Nmap | An open-source utility used for security audits that scans TCP ports on hosts. |
| Arp scans | ARP scans identify devices on local subnets, allowing teams to see which devices are on the network. |
| Simple Network Management Protocol (SNMP) | A protocol to help inventory network devices. Network devices can be discovered by Device42 using SNMP v1, v2c, or v3. |
| OpenVas | Open source vulnerability scanner |
Specialized asset management platforms like Device42 include several of the tools mentioned above, as well as other tools and techniques to discover hardware and software assets in data centers and cloud environments.
Once discovered, the tool should inventory the asset and add it to an accurate configuration management database (CMDB). Everything should be inventoried so that there are no rogue assets that an attacker can use to pivot into your network. A CMDB will be one of the most important backbones of a vulnerability and patch management program.

Practical questions
Here are some recommended questions that every engineer should ask before remediating vulnerabilities:
| Questions | Description |
|---|---|
| What are the assets under scope? | This question helps give ideas about what assets the security team should focus on. It could be as small as a cloud instance or as big as the organization’s network. |
| What are my scan targets? | When using a vulnerability scanner, this question helps to ensure you’re scanning the right assets. |
| What systems, applications, and services are heavily utilized? Which are not? | This helps to reduce redundancy and overexertion for less critical assets. Remember, the assets you care about are the ones that have a high business impact. |
| Who is responsible for administering patches on the asset? | When a vulnerability is found and the asset is deemed critical, it should be remediated within a reasonable time. This helps determine who to contact if a patch is not applied (or who to give kudos to if the patch is applied before you even need to ask). |
| Who is the relevant stakeholder for the examined application/system/infrastructure? | This helps determine the go-to person for any questions related to the asset. A lot of times, security engineers may only know that they need to patch a server. It helps a lot more when you understand what the server that needs to be patched does. |
Maintain an accurate configuration management database
A CMDB’s value is tracking an organization’s assets and data flows. It can help map asset dependency to support change controls, vulnerability mapping, and faster incident response.
A CMDB should not just be used to track an organization’s Configuration Items (CI) or devices. It should also cover interdependencies, relationships, and data flows that these CIs have with each other.
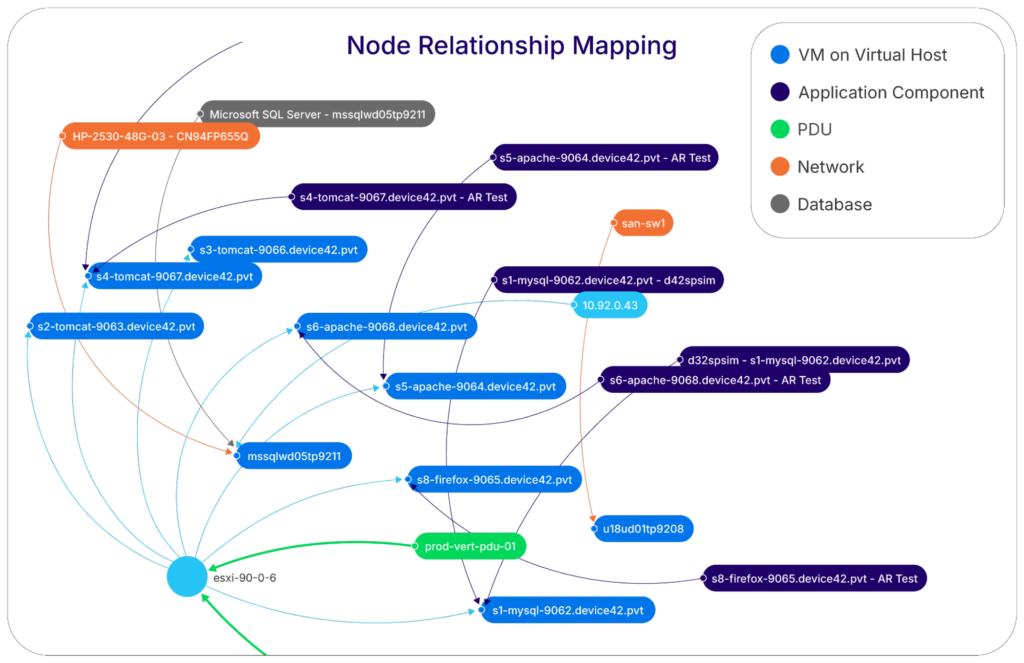
Example of CMDB Mapping (source)
Key things a CMDB must cover:
| Configuration Items (CI) | Attack surface components the organization tracks, including software, hardware, networks, cloud environments, and even end-user devices. |
| Relationships | The interdependencies between CI. For example, is a specific software deployed in one of the multiple cloud environments that the organization manages. Interdependencies help with attack surface mapping. |
| Attributes | CI attributes are based on technical aspects or operational assignments and must be managed and verified for effective utilization. |
| Changes | For effective vulnerability and patch management, the CMDB should also be able to track the changes that occur to the CI. For example, teams can track if an operating system is outdated, when it needs to be patched, when it was last patched, etc. |
Vulnerability and patch management programs rely on a CMDB as the backbone of an effective strategy. Any tool can be used as a CMDB as long as it tracks:
- All assets
- Their relationship to other assets.
- Their associated vulnerabilities
- Patches applied
However, using simple tools such as a spreadsheet can lead security engineers to focus more on tracking assets than remediating vulnerabilities. For that point, a central management tool that can provide full transparency is more efficient. Following CMDB best practices makes identifying and remediating vulnerabilities more effective and efficient.
Integrating all assets found during asset discovery and tracking changes allows for better risk management. Tools such as Device42 allow a generative view of all assets with API integration so that you can have an all assets dashboard in your organization. If you want a deeper dive into the nuances around a CMDB, check out the article linked here.
Perform risk-based prioritization
You might have a list of assets and their associated vulnerabilities at this point. Patch prioritization is not just looking at Common Vulnerabilities and Exposures (CVE) severity as the determining score, but also the exposure, exploitability, and business impact that a patch may have on the business. While two vulnerabilities may have differing NIST Common Vulnerability Scoring System (CVSS) ratings, other environmental factors must be considered to accurately measure existing risk.
Risk calculation methods
One way to calculate the risk is to take the CVSS against the asset’s perceived criticality and exposure. For example, a security engineer can ask themselves how they quantify the asset on a scale of one to ten and the exposure of the asset to externalities on a scale of one to ten. This is only an example, and teams can modify it as they like, but it shows a way to quantify different measurements to get a risk rating.
| Example | NIST CVSS | Risk Impact |
|---|---|---|
| An internal web server was found to have the critical vulnerability Log4Shell, a zero-day that was described by the industry as one of the most critical vulnerabilities ever seen. This server lives in an isolated subnet that can only be accessed with an internal VPN, for which a few members have permission. In addition, the server is no longer in use, no outbound connections are allowed, and it stores no sensitive data. | 10.0 – Critical | Low |
| A web server connected to the internet is found to be vulnerable to CVE-2020-35700, which allows attackers to execute arbitrary SQL commands. These commands can be used to tamper with a critical DB, since the permissions on the SQL database are largely public. | 8.8 – High | High |
Assets that have the most exposure should be prioritized first.
The two examples above show how prioritizing remediation on only a CVSS score causes teams to miss a higher risk situation elsewhere. In fact, sometimes, chasing only critical vulnerabilities leaves the engineer focusing on the tree with a risk of missing the whole forest!
Other metrics that are available to use alongside the CVSS score are First’s Exploit Prediction Scoring System (EPSS) and CISA’s Stakeholder-Specific Vulnerability Categorization (SVCC). Both scores consider exploitability when deciding the risk impact on the organization. EPSS also considers whether the vulnerability is being actively exploited to generate an all-encompassing risk score.

Asset prioritization example (source)
Tools like Qualys can return detailed vulnerability reports, which can be paired with open source intelligence (OSINT) for teams to determine a vulnerability’s risk on the organization. Remember, risk prioritization is different for all businesses. Ensure that your organization prioritizes the most important ones to the business and security needs to effectively mitigate threats.
Ensure effective communication and integration across cross-platform teams
Ensuring constant communications and having a defined plan to assign ownership of assets to responsible team members, especially assets with prioritized patching cycles or critical vulnerabilities, will ensure a smooth vulnerability and patch management operation. Once risks are identified, responsible teams must work on remediating the risk immediately.
This lists the most common stakeholders involved in the vulnerability management process.
| Role | Description |
|---|---|
| Security engineer | Responsible for consolidating vulnerabilities, effective communication with stakeholders, providing guidance on remediation, and risk prioritization. |
| System admin | Responsible for remediating the vulnerabilities that impact the system. |
| Application developers | Responsible for remediating the vulnerabilities that impact the application. |
| Engineering managers/leadership team | Ensures vulnerability management is prioritized in project timelines, facilitates communications, and prioritizes around the operational and business impacts. |
A CMDB can tie back and provide information on which assets are under whom to help decide the relevant stakeholders to loop in on communications. Stakeholders can plan on how to tackle the most high-impact items, with clear transparency on the process that will be taken to patch and remediate the vulnerabilities found.
Automate patch management
Patching can be a long, manual process, so automating deployments and integrating existing solutions is always better. Not only does this reduce an organization’s exposure window, new solutions such as Infrastructure-as-Code (IaC) make keeping track of patches and changes easier than ever.
When patching, follow a blue-green or canary deployment model. Organizations typically segment their environments into development, staging, and production. A patch fixes vulnerabilities, but it can also cause unexpected system behavior. Patching systems in development helps ensure stability in production. With an infrastructure-as-code automation tool like Terraform, an engineer can have a documented understanding of the environment’s current state. As such, they can easily track changes across the different environments.
Another popular tool for patch management is Ansible. For example, Ansible runs playbooks that security engineers develop to install security updates across clients and perform other system admin tasks. This helps reduce system administrators’ time patching machines and allows them to focus on other operational tasks.
For example, let’s say a vulnerability requires a Linux configuration to update the cryptography host key algorithms SSH uses. Rather than manually updating each machine one by one, you can write an Ansible playbook that changes the configuration file across all target hosts at once.
The Ansible code would look as follows:
---
- name: Configure compliant SSH HostKey Algorithms
hosts: my_ec2_instances
become: true
tasks:
# Update the ssh file with the compliant host key algorithms
- name: Update sshd_config
replace:
path: /etc/ssh/sshd_config
regexp: '^#?HostKeyAlgorithms\s+.*'
replace: "HostKeyAlgorithms [email protected],curve25519-sha256,diffie-hellman-group18-sha512,diffie-hellman-group16-sha512,diffie-hellman-group14-sha256,diffie-hellman-group-exchange-sha256
"
register: sshd_config_change
# Restart the SSH daemon if changes occurred
- name: Restart sshd
service:
name: sshd
state: restarted
when: sshd_config_change.changed
The code enables the configuration of compliance across multiple hosts at a fraction of the time it would take a system admin to perform the task. Take advantage of the technologies available and automate as much as you can.
Reframe success metrics: measure and report risk reduction
Vulnerability management is a continual risk reduction process. No one-size-fits-all metric applies to a successful vulnerability and patch management plan; instead, it identifies what success metrics can be quantified and measured over time.
What can be measured can be improved. Measurable plans with vulnerability and patch management incrementally improve your organization’s security posture.
Rather than aiming for a broad “no vulnerability approach,” track small achievable measurements and show incremental progress, i.e.,
- The implementation of daily scans helps reduce critical vulnerabilities on external-facing web services by 90% in a week.
- The new addition of automation tools reduces patching time by 50%.
- 88% of assets have zero high or critical vulnerabilities
- Newly implemented scans cover 85% of all assets, etc.
Focusing on quantitative measurements allows the team to see if remediation and patch efforts effectively cover the attack surface.
When measuring risk, there are two points that each measurement should hit:
- Focus on asset-specific details for technical teams so they can remediate and understand their attack surface.
- Focus on risk reduction in relation to the business so that executives can make operational decisions on what to prioritize (or not prioritize).
Using a CMDB, one can also track compliance and changes to a CI’s risk level. The level of risk associated with each asset is identified in the earlier stages (threat modeling, vulnerability scans) and then monitored continuously afterward. Use the CMDB to measure the risk levels and what works and does not.
Conclusion
Vulnerability and patch management best practices involve multiple proactive steps to help mitigate threats against an organization. Patching vulnerabilities when found is often not enough. It takes a detailed understanding of what assets are at risk, identifying how to track vulnerabilities to these assets, and having strong communication to secure them when needed.
A proactive plan is the standard in good vulnerability and patch management. Doing so ensures that you continually reduce risk to your organization instead of reacting to threats when they happen.