Data Center Environmental Monitoring: Concepts and Systems
Data center environmental monitoring is the process of collecting key metrics related to the operating conditions of a facility to manage costs, lower power-related CO2 emissions, and avoid heat or humidity problems that can impact equipment. Examples may include facility and system temperature, relative humidity, power consumption, and total airflow. An environmental monitoring system (EMS) is typically an array of sensors and dashboards used to collate the collected data and display it in a usable format for data center operators.
Modern EMS solutions are always improving and changing to meet new DC challenges, utilizing more sophisticated sensor technologies that give precise insights into the health of the environment within, near, and around equipment racks. Effective utilization of these tools will help data center operators make informed, data-driven decisions and potentially mitigate the risks associated with environmental issues.
The steps needed to monitor environments include the installation of sensors in preorganized or modeled locations, integration of these sensors into some digital framework, and establishing a concept of operations (CONOPS) document for responding to sensor output. The EMS will allow for the analysis of environmental information as raw data, graphs, or trend charts. It may also include integration with data center infrastructure management (DCIM) software to create a cohesive management framework.
This article will detail the various metrics that can be collected by an EMS, discuss how an EMS can be implemented, and present recommendations both for integration with existing data center management systems and ensuring alignment with overall organizational environmental impact goals.
Summary of key data center environmental monitoring concepts
| Why use an EMS? | Environmental monitoring systems increase both the overall efficiency and efficacy of facility maintenance. |
| EMS metrics | Environmental monitoring systems collect data about temperature and humidity, airflow, and power consumption, which is centralized for maintainers. |
| EMS implementation | Implementation is based on a process of architecting a sensor network and developing a user interface and a concept of operations (CONOPS) document. |
| DCIM integration | It is possible to utilize the EMS tools as a force multiplier for DCIM management software and operational principles, enhancing overall organizational success. |
| Recommendations | EMSes are only as functional as the design and architecture affords, so it’s necessary to understand needs and provide the best solution for each particular situation. |
| Final thoughts | Environmental monitoring is required at all levels of operation, and an EMS enables a centralized, efficient maintenance model to enhance sustainability and reduce data center costs. |
Why use data center environmental monitoring (EMS)?
Monitoring is an essential component that helps assess performance and mitigate potential issues at every level of systems operations. Whether discussing the operation of a single piece of hardware, a larger hardware rack, or the entire physical infrastructure of a data center, monitoring is a necessary feature embedded in design.
The graphic below illustrates the fundamental components of an EMS, identified at the rack and component level, where a set of sensors gather data that is then routed via a TCP/IP network to a central user interface. The complexity of this sensor network, the locations of sensors in and around rack hardware, and the nature of the management servers or user interface are functionally dependent on the specific instantiation of a facility’s EMS. However, regardless of the type of network infrastructure or the nature of the data collected, the fundamental operating principles remain the same:
- A scalable sensor network collects a broad set of environmental metric data
- The data is collated by a central management repository into a user interface
- The collated data is then used to identify facility waste or operational issues
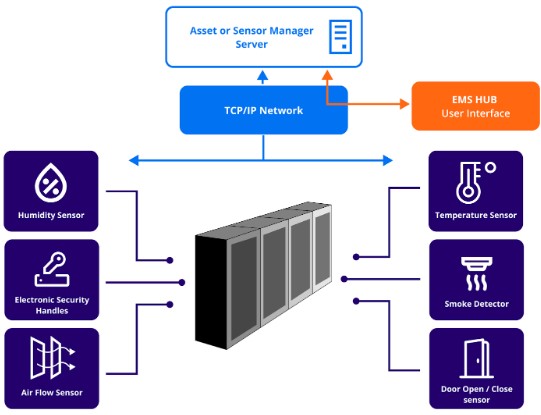
A general model of a data center environmental monitoring system (EMS)
Scale-independence
Individual hardware components, such as servers, have processors running internal status checks and monitoring temperature, storage availability, and network presence. At a larger scale, hardware racks monitor the presence of power via power distribution unit (PDU) or automatic transfer switch (ATS) interfaces. Going further up in scale, the overall facility’s heating, ventilation, and air conditioning (HVAC) systems typically have thermal, airflow, and smoke-detection sensors installed as a fundamental part of their architecture.
Each of these elements generates usable data, and it is up to the operators to use that data to make informed decisions. An EMS uses this disparate data—either in conjunction with additional external sensors or on its own—to generate a characterization of the facility that each data set could not provide on its own.
Fundamentally, the scale and exact implementation of the EMS is up to the user, just as it is dependent on the specific hardware and infrastructure being monitored, but the utility of an EMS is scale-independent. Whether an EMS is installed to monitor a set of components, a set of racks, or an entire facility, the aggregated data will provide emergent qualities that the individual subsystems could not provide on their own.

Centralization
Given the presence of disparate systems and subsystems that all provide similar datasets that help characterize the operational environment of a system, an EMS provides value by synthesizing all of this data into a single management server and user interface. The value here is in aggregation: the generation of unique performance metrics and data that would otherwise be opaque to the user without the centralization of data.
This synthesis allows for a global approach to system operation/maintenance that can cross-reference data points and help inform both operators and users. Examples of this may include:
- Using time-based point plots to help identify localized power sinks: Identification of this sort of characteristic behavior could necessitate moving racks or components to balance power or thermal load
- Identifying environmental changes that are yet to be identified by other means: For example, individual components may be triggering humidity alarms that indicate a leak or environmental contamination before they are identified by maintainers.
An environmental monitoring system is a tool that leverages a network of sensors, detectors, and alarms to provide the most accurate, real-time account of a facility. This saves time and money by consolidating inspectable interfaces into a centralized hub while also improving overall performance.
Design optimization
The goal of a data center is to fulfill operational requirements, maintain interruption-free service, and manage the facility systems in a way that is optimized for efficiency. An EMS in conjunction with DCIM can be used to optimize how a data center functions in many areas:
- Identifying waste or unnecessary overhead
- Isolating high-risk elements or systems
- Reducing total maintenance costs
EMS metrics
The metrics or data sets collected by an EMS are broadly based on the infrastructure and specific hardware elements in a system. For example, networking components might require real-time monitoring of bandwidth or throughput values, whereas storage hardware would require a highly accurate representation of available space. There are key environmental values that must be measured in every data center, regardless of application.
Temperature and humidity
Temperature is self-explanatory, in the sense that a temperature sensor will work to identify changes in ambient temperature in the same way that a household thermometer works. The data from a temperature sensor comes in only as a flat value, and it is up to the EMS to incorporate set points based on key operational limits. Increases or decreases in temperature past key operating limits may result in degraded performance, in some cases leading to the full shutdown of operational hardware.
When it comes to humidity, there are two distinct measurements:
- Absolute humidity is the amount of water vapor in the air, technically the mass of water vapor divided by the mass of a given volume of dry air at a given temperature.
- Relative humidity (rH) is the percentage of water vapor that the air can hold based on its temperature or the ratio of the current absolute humidity to the total possible absolute humidity based on the given temperature.
As the air cools, the rH percentage increases until the dewpoint temperature is reached, at which point rH nears 100%, and water droplets begin to form via condensation. The rH must be kept below 90% to avoid the risk of condensation. However, overly dry air is also problematic: For the safe operation of data center equipment, it is critical that the rH be maintained at 10% or higher, preventing static discharge that can damage components.
In general, the ideal ambient humidity for a data center is somewhere between 45-55%; individual components typically have operational ranges of 20-80% rH. Additionally, having early-warning alerts programmed into an EMS at 40% (on the low end) and 60% (on the high end) can help mitigate humidity-related risks.
Because of the importance of maintaining the correct levels, temperature and humidity sensors—which are typically implemented via combination sensors—must be installed and monitored regularly.
Airflow
The amount of airflow in and around data center equipment is the next most important environmental metric after temperature. Airflow should be sufficient to effectively match the input requirements of the internal component cooling fans. If, for example, a rack of server equipment has a requirement of 160 cubic feet per minute (CFM) per kW of power, then the computer room air conditioner (CRAC) must move enough cool air to match that demand. Should the provided flow be insufficient, hot air may recirculate back to the equipment, increasing internal temperatures until critical thermal runaway scenarios occur.
An EMS used in the context of airflow or air circulation incorporates critical design requirements or real-time design changes, helping to identify these high-risk conditions before they result in disruption of performance. Furthermore, by collating this data into a central hub or user interface, airflow characteristics can be easily examined by the operators and maintainers without the need to evaluate individual component, rack, or regional environmental conditions.
Power quality and consumption
All data center hardware needs constant, continuous electrical power, and its quality can be described in two ways.
The first is in terms of the delivered voltage and frequency stability provided by the utility. This can be monitored at the electrical meter and may be adjusted with external power filtering or correction components.
The second way to describe electrical needs is in terms of the power (kW) or current (amps) demand. In terms of current, it is crucial to monitor both the current entering the facility (total load/demand) and also individual cabinet/rack consumption.
Having an approach that is scale-independent allows the identification of outages or power quality deviations as quickly as possible, thereby easing the implementation of backup plans or systematic shutdowns.
Furthermore, having a holistic monitoring solution that considers both delivered stability and overall load will help increase efficiency, decreasing waste and reducing cost.
Data center environmental monitoring system implementation
EMS implementation relies on two interrelated processes:
- Evaluation of the goals of the installed system: Key performance goals may include decreased maintenance costs, optimization of white-space cooling, or a general decrease in power consumption. These goals must be evaluated in terms of net outcomes, i.e., whether the cost of the installed system will be covered by the net gains of implementation. Based on this calculus, the key requirements of the employed EMS will be identified, such as the quantity and capabilities of sensors or the type of network infrastructure and data storage.
- Aggregated data output and user interface: Once the goals are set, the aggregated data and user interface needs to be designed or selected (if using a consumer off-the-shelf interface). The structuring of the IT system used to gather and display data—both in terms of how that data is accessed and how it is aggregated to generate trending or performance mapping—is key to operators using that data to make informed decisions.
Once the goals and user interface are established, thereby helping to create a plan and ROM (rough order of magnitude) for cost and installation timeline, then the CONOPS document can be developed to action the received data in an effective and efficient manner. Implementation, therefore, starts with the design of the system to meet management goals and ends with the necessary operational standard operating procedures (SOPs) associated with its use.
Sensor layout and design
The architecture of an environmental monitoring system relies on specific hardware and software components that come together to form an integrated communication system. Accordingly, the design of an EMS can be described in a type of stem-leaf configuration, where the individual sensors (leaves) work together to send data up the chain of network hardware (stems) into a central hub.
These sensors may be embedded in the operational hardware that is already installed in a facility, such as internal server temperature and power consumption sensors, PDU/UPS power quality sensors, or HVAC airflow and thermal sensors. If the only sensors used in an EMS are already internal to facility hardware, sensor layout would functionally be the routing of this data to a central server. Alternately, external sensors may be added in conjunction with the internal sensors already present in a facility, again relying on the EMS to aggregate both internal and external sensor output in a way that characterizes the entire facility’s performance.
If the goals and performance expectations of an EMS require the use of external sensors, they need to be selected based on specific operational or detection characteristics. Examples may include specifications on thermal sensors used to evaluate ambient temperature for a specified area within a specific tolerance, or with the added feature of detecting humidity. (As mentioned earlier, temperature and humidity sensors are typically integrated into one unit.)
Electrical sensors, which vary in terms of their application and design, can be selected based on where power is monitored: at a component, an outlet, or the meter. Each external sensor would then need to be connected either wirelessly or through a network tether, using a TCP/IP framework, to feed information through routers or switches and eventually to a central server for processing. As mentioned before, whether the sensors are external or internal, the layout and design of an EMS depends on the effective routing and collation of this sensor data into a user interface.
Software user interface
Once data has been collected, routed to a central repository, and analyzed based on timestamp or priority (based on the nature/urgency of the information), it needs to be displayed in a format that is easily accessible to operations personnel. The development of an effective graphical user interface (GUI) is key to the overall efficacy of an EMS.
Most software suites that are used to collate data from EMS sensors include a standard monitoring interface. The specific use case of the system or goals of the EMS can help direct what sort of software (and, thus, GUI) would be the best choice.
Suppose, for example, that the user interface supplied via an off-the-shelf solution only allows for a certain type of sensor monitoring, such as electrical sensors providing total power consumption of racks or the overall facility, but the general needs of the facility dictated more dynamic monitoring of power quality and time-based performance metrics. In this case, a custom solution might be necessary that could determine quality metrics such as voltage drop from the utility source to individual PDUs or distribution points (subpanels or boards within the facility).
A custom solution to this problem might leverage additional, external sensors and could include a coded interface that provides a tabular display of active sensors, a facility-wide layout that indicates where sensors are located and their alarm state, or even graphical displays that overlay real-time data with alarms or performance characteristics. This new, dynamic solution would be able to help illustrate the need for power reliability hardware (such as capacitor banks), identify components or racks that are at risk of degraded performance, and create trend plots that show the changes of operational characteristics over time.
CONOPS
A concept of operations (CONOPS) consists of a set of procedures used to operate a system or a set of steps used to deal with specific events. In terms of an EMS, CONOPS can relate to the operation of the EMS, like monitoring periods, which may include the length that data is trended or the frequency of operator inspection of the user interface. Functionally, this would specify both how the output data can be used and the hourly responsibilities of maintenance staff.
For example, if a trending tool is used to collate data over the course of a day, the CONOPS for this aggregate set of data may be to evaluate daily performance and action any discrepancies on a daily cadence. Similarly, if the expectation is for the user interface to be monitored twice a day, following a checkout procedure that is associated with handoffs between day and night staff, then this EMS CONOP would require maintenance staff to spend a certain amount of their working hours performing this checkout.
In terms of risk mitigation or problem-solving, should an EMS send an alarm or alert, the CONOPS would include specific SOPs for dealing with performance anomalies. If, for example, an electrical fault is triggered, then there should be a procedure in place to avoid damaging the powered hardware. This may mean that at the sign of a specific power fault, one PDU should be remotely shut down and the hardware components be shifted to backup power. Similarly, should the temperature or humidity in a facility change dramatically, then there should be a procedure to react and move the values back to normal. This may mean a manual or remote changing of the HVAC settings to decrease or increase facility temperature. In either of these cases, practical responses can be automated by component management systems, something an EMS may be able to accomplish with proper planning, or they may require operator intervention.
DCIM integration
Data center infrastructure management is both a set of functional tools—typically a software suite used to model and maintain operational systems—and a set of principles that guide the overall design and operational requirements of a facility. An effective EMS will allow for the generation of new data that is trended and charted in a way that can help be predictive as well as risk mitigating; it will also increase the overall informativeness of existing DCIM systems. This is chiefly due to the centralization of operations in a user-defined environment, but it is also important to note that the sensor network associated with an EMS will add multiple layers of observables that would otherwise be missed.
EMS systems and DCIM design
Monitoring complex systems can be highly labor intensive, whether it involves physically inspecting the various infrastructure systems or ensuring adequate response time to stop a problem before it progresses into something more serious. And the single biggest issue with data center management is human error.
DCIM software solutions work to solve this problem through various automated processes, such as ticketing systems to report faults or issues, configuration management tools to identify whether key documents or repair statuses have been modified, and even building management systems that operate much in the same way that a small EMS may function: controlling ventilation, lighting, or building security systems. However, missing elements in the monitoring tools associated with DCIM software can arise in the form of incomplete aggregation of environmental data taken at each level of facility operations.
DCIM systems are only as good as the data they can provide, meaning that the automation tools associated with DCIM can only help solve problems that are immediately apparent from the analysis and interrogation of the collected data. Without a comprehensive EMS incorporated into a DCIM suite, there will be pieces missing: key data trends that emerge from the performance data of both internal hardware and external facility sensors.
Fundamentally, effective data center management is all about the data and centralized access to it, and a DCIM system without an EMS will always be lacking in both key areas.
EMS improvements to DCIM
The idea of automation in terms of data center infrastructure management may seem complex or unnecessary; or, as stated before, it could be that the DCIM software currently being used by an organization boasts its own set of automated tools. The reality is that there is always room for improvement, even with the most robust automation tools in place.
An EMS can add several important layers to existing DCIM software, including highly specialized monitoring sensors that can provide real-time performance metrics on a system. Implementation of an EMS could, for example, provide additional information about individual component rack power consumption, down to the minute details of hour-by-hour demand. Alternatively, an EMS could provide important information about airflow and cooling in a facility that a DCIM or building management system (BMS) could not because an EMS can incorporate both the rack and ventilation sensor data sets.
Ultimately, it may be possible to match the powerful trending and real-time data aggregation of an EMS by manually running calculations on the outputs of a standard DCIM tool or software suite. However, the implementation of an EMS allows operators to action data instead of searching for it.
Recommendations
An EMS is, fundamentally, a toolset that allows for the monitoring and evaluation of facility performance characteristics better than any standalone system. The most important metrics of EMS success are ones that can demonstrate a net benefit to the system as a whole. This may mean a decrease in maintenance costs through automation, better data aggregation via an embedded sensor network and processing hub, or powerful trending tools that can help inform all stakeholders of the risks and opportunities associated with facility operations. The data generated by this type of system can be used for maintenance, operational improvements, and even forward-leaning estimates of growth capacity and overhead.
There is another aspect, however, that is tied more into the broader impacts of operational requirements. An EMS can be used to calculate the net costs to the non-facility environment, captured in terms such as carbon footprint and operational emissions. In this way, an EMS can be used not only to improve the bottom line of a facility but also as a tool to evaluate whether a facility is meeting environmental benchmarks set by a company or organization.
Some of the main criteria when designing and implementing an EMS are a function of how well these benchmarks can be identified and how operational costs and impacts can be shaped to meet them. Using carbon footprint as an example, an EMS can help determine a facility’s emissions, not only identifying key consumption metrics but also trending them out into future expansion or growth. This may necessitate future investments in carbon offsets or the implementation of sustainable countermeasures, such as renewable energy sources and higher-efficiency HVAC/lighting systems.
Best practices and key recommendations associated with the planning and deployment of an EMS are ultimately a function of the goals of the organization employing it. Striking the right balance between efficiency and net environmental impacts is a calculus that should go into the overall design and budget of a management system, not specifically limited to the EMS sensor or data network being used, but also in the aggregation capabilities associated with the processing servers and user interfaces. By understanding a facility’s needs, and understanding the larger goals of the parent organization, an EMS can be used to increase profit while also meeting each of these operational benchmarks well into the future.

Fastest time to value with easy implementation and agentless asset discovery
Comprehensive hardware and software inventory management

Broadest discovery from legacy technology to the latest cloud and containers
Final thoughts
An environmental management system can take a number of forms. It can be used as a separate system from the larger DCIM architecture that is not embedded into the DCIM framework utilized to maintain system operations. An EMS can also be used in concert with DCIM solutions, adding a fundamentally limitless set of data points to be aggregated and collated as the users see fit.
In any case, an EMS allows for a framework that can help meet key environmental impact goals, helping an organization understand the costs of operations both to its bottom line and the greater environment that it inhabits. Regardless of the implementation, data center environmental monitoring and modeling can be instrumental in the centralization of important performance metrics, allowing maintainers and users the opportunity to understand their systems better.